贝叶斯定理
P(X∣Ci) 表示 X 在类别 i 下的条件概率
P(Ci∣X)=P(X)P(X∣Ci)P(Ci)
P(X∣Ci) :
- P(XCi)由样本中统计 i 类别下 X 的数量得出
- P(Ci) 根据具体情况给出
此处的 X 是一个属性的取值。
贝叶斯决策的准则为:
若对任意的 j 和特定的 i
P(Ci∣X)>P(Cj∣X)
则 X 属于类别 i
假设 X 属于类别 c , P(c) 代表类别 c 的概率,P(X) 表示的是样本 X 的概率,P(X∣c) 表示一个物品是 c 类别的情况下它是 X 的概率,则可以求出这个物品是 X 的情况下他是 c 类别的概率
P(c∣X)=P(X)P(X∣c)P(c)
但是类别不至有一个,找到物品确定是 X 的情况下,最有可能属于的类别需要这样子计算:
max(P(ci∣X))=maxP(X)P(X∣ci)P(c)
也就是遍历所有类别,一个一个算,求出里面最大概率的情况下的 ci 就被称为 极大后验假设,记作 cmax 也就是
cmax=argmaxc∈CP(X)P(X∣ci)P(c)
由于是求最大,不是求具体的数值,所以可以忽略共同因子 P(X)
在没有类别概率 P(c) 的情况下,可以假设每个类别的概率相等,所以再忽略 P©
cml=argmaxc∈CP(X∣c)
这就是极大似然概率
朴素贝叶斯分类算法
朴素的假设:属性的类条件独立性。就是在指定类别的时候,属性之间是相互独立的。
X 由属性 {x1,x2,...,xn} 组成
想根据贝叶斯公式求解最大后验假设,我们需要先有 P(X∣Ci) 和 P(Ci)
由于朴素假设,所以可以直接计算(所有属性的条件概率累乘)
P(X∣Ci)=j=1∏nP(xj∣Ci)
最大后验假设:
imax=argmaxi≤mP(Ci)j=1∏nP(xj∣Ci)
这就是朴素贝叶斯分类器进行分类的依据,类别 imax 就是样本 X 所属的类别。
工作过程:
遍历所有样本 X ,根据朴素假设下的贝叶斯定理,将 X 判断为最大后验假设的那个类别。
- 如果 P(Ci) 未可知,则假设他们相等(在计算中可以直接忽略),也可以用样本中 Ci 所占的比例对 P(Ci) 进行估算。
- 如果属性 Ak 是连续值,则假设它服从正态分布;如果是离散的,则按照样本中,指定类别下该属性为指定值的比例来计算 P(xj∣Ci)
算法描述:
- 样本离散化处理、缺失值处理。
- 遍历样本集,将类别数量、类别下的属性取值的样本个数构成统计表。
- 跟据统计表计算 P(Ci) 和 P(Ak=xi∣Ci)。
- 构建分类模型为贝叶斯最大后验假设。
- 遍历数据集得到分类结果。
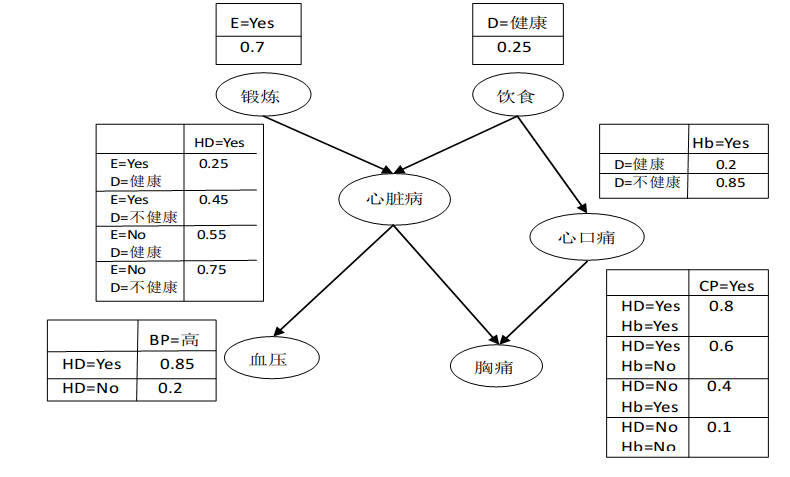
贝叶斯信念网
朴素假设太严格
用图形表示一组随变量之间的概率关系:
- 有向无环图,表示变量之间的依赖关系。如果一个节点的父节点已知,则他对他的上层的其他所有节点独立
- 概率表,把各节点和它的直接父节点关联起来。若 X 的父节点是 Y,则包含 P(X∣Y),若没有父节点则只包含 P(X)