Hadoop 课程笔记:YARN 介绍
MRv1 的缺点
MRv1 由一个 JobTracker 和多个 TaskTracker 组成,JobTracker 负责作业(job)的初始化以及监控、资源调度等所有工作。存在不足:
- 扩展性差,难以支持 MapReduce 之外的运算
- 资源利用率低
- 可靠性差,易造成 NameNode 单点故障
MRv2
MRv2 引入了 YARN,即:
- 增加了 ResourceManager 和 NodeManager
- ResourceManager 负责应用管理(ApplicationManager)和资源调度(Resource Scheduler),在执行 MapReduce 任务时类似于 MRv1 中的 JobTracker;
- NodeManager 负责节点运行,容器(Container)的启动和释放,在执行 MapReduce 任务时类似 MRv1 的 Task Tracker
使用 YARN 可以做到一个集群中运行多个大数据框架,也就是把 Application 和 Resource 抽象了出来,不再和 MapReduce 紧密结合。
YARN 作业处理流程
- 用户向 YARN 中提交应用程序,应用程序中有 Application Master 程序,启动 Application Master 需要执行的指令、用户需要执行的业务功能(用户程序);
- Resource Manager 为程序分配一个 Container,并让负责该 Container 的 Node Manager 在 Container 中启动 Application Master。Application Master 将负责数据的切分,以及为用户程序申请资源,并分配给子任务,并监控子任务与容错;
- Application Master 在第一个容器中启动后,将向 Resource Manager 注册,这样用户可以直接通过 Resource Manager 查看应用程序的运行状态。Application Master 还将为用户程序需要执行的任务申请资源,监控这些任务的运行状态;
- Application Master 通过RPC协议进行轮询不断向 Resource 申请资源(容器);
- Application 成功获得资源后,将于负责该资源的 NodeManager 通信要求其启动任务;
- Node Manager 为任务设置好运行环境后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
- 所有任务通过 RPC 协议主动项 Application 汇报状态和任务进度
- 应用程序运行完成后,Application Master 将告知 Resource Manager 并使其关闭 Application Master 所在的容器。
从这些步骤中可以看出,YARN 使用的是基于 Resource Manager 和 Application Master 的双层调度。
YARN 调度机制
FIFO Scheduler:先进先出
Fair Scheduler:公平调度器
Fair调度器的设计目标是为所有的应用分配公平的资源(对公平的定义可以通过参数来设置)。公平调度在也可以在多个队列间工作。举个例子,假设有两个用户A和B,他们分别拥有一个队列。当A启动一个job而B没有任务时,A会获得全部集群资源;当B启动一个job后,A的job会继续运行,不过一会儿之后两个任务会各自获得一半的集群资源。如果此时B再启动第二个job并且其它job还在运行,则它将会和B的第一个job共享B这个队列的资源,也就是B的两个job会用于四分之一的集群资源,而A的job仍然用于集群一半的资源,结果就是资源最终在两个用户之间平等的共享。
Capacity Scheduler:容量调度器
Capacity 调度器允许多个组织共享整个集群,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。除此之外,队列内部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源了,在一个队列内部,资源的调度是采用的是先进先出(FIFO)策略。
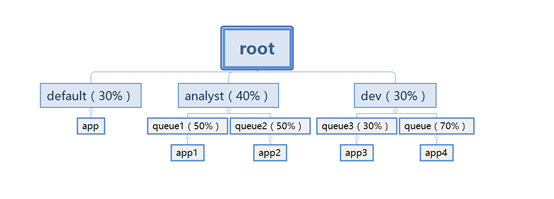
- 资源按比例划分
- 层级队列划分方式
- 资源抢占(若队列中有空闲资源,其他队列可以抢占该资源)
YARN 资源调度语义
资源调度语义即 YARN 支持的资源调度操作
支持:
- 请求特定节点或机架上的特定资源量
- 将某些节点移入黑名单,并不再使用节点上的资源
- 请求归还资源
不支持:
- 请求任意节点或机架上的特定资源量
- 筛选一组或几组资源
- 细粒度的资源
- 动态调整 Container 资源