Transformer
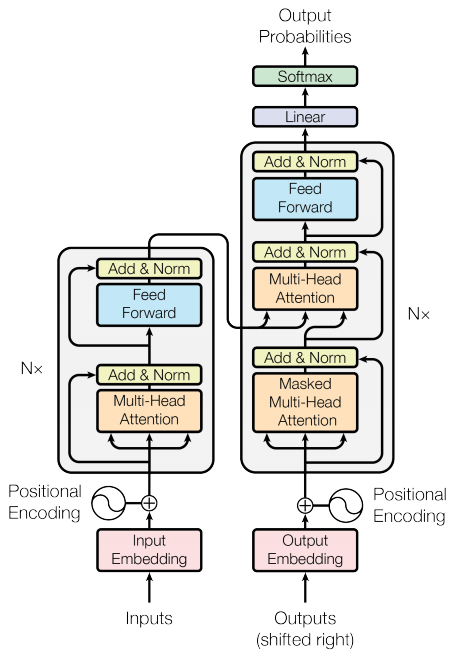
本文是对 Transformer 的学习笔记,其中的所有代码均出自于 Github,仅用于辅助理解使用。
本文的组织方式是根据 Transformer 的架构图逐个介绍,然后介绍其训练和推理的过程,最后介绍一些细节。
由于在 NLP 领域的零基础以及 DL 的薄弱基础,学习原始的 Transformer 都耗费了 3 天的时间,以此篇论文作为阶段性的总结。
Input Embedding
将输入的文本序列转化为通过 Embedding Matrix
记录了词汇库中的所有词汇的 Embedding Vector,其大小是 ,也就是向量长度x单词数量; - 输入的文本序列根据
中为每个单词指定的向量进行拼接; 是随着训练的进行逐渐学习的,它的实际形式是一个神经网络的参数。
随着训练的进行,单词所对应的向量在高维(GPT3: 12288维)空间中:
-
意义相近的单词位置相近,它们向量上的差距可以表示它们实际概念上的差距;
表示某个 的嵌入向量; 这代表着,我们可以利用这些量化后的概念差距,来将一个领域内的变化转化到另一个领域内的变化。比如我们可以直接用性别概念的差距,来将 Father 转化为 Mother
-
让蕴含着相同概念的单词有着相同的方向(在某个投影上它们指向同一方向),比如
(周润发, 刘德华, 男性)都在某个投影中指向同一个方向, 以及(周润发, 刘德华, 演员)(周润发, 刘德华, 四大天王)。可以用点积(元素相乘再相加,结果是标量)来衡量向量之间的对齐程度。相近时点积为正,垂直时点积为0,相反时点积为负。
Positional Encoding
在经过 Input Embedding 后,得到的
Transformer 所使用的编码方式为:
其中 pos 表示序列中的第 pos 个单词,
在输入下一步之前,我们将 Positional Encoding 和 Input Embedding 相加。为了避免他们的尺度相差过大, Input Embedding 会乘以
PE 具有平移可加性。平移可加性指的是:两个位置之间的距离(
也就是说:两个位置的编码之间的差异是有规律的,可以被神经网络学习到。
为什么要用
- 维度越小(靠前),频率越高(周期越短)
- 维度越大(靠后),频率越低(周期越长)
这样,位置编码整体上就可以覆盖从细粒度的局部位置到粗粒度的全局距离。举个例子:
- 当
,指数是 0 → 频率是 - 当
,指数是 1 → 频率是
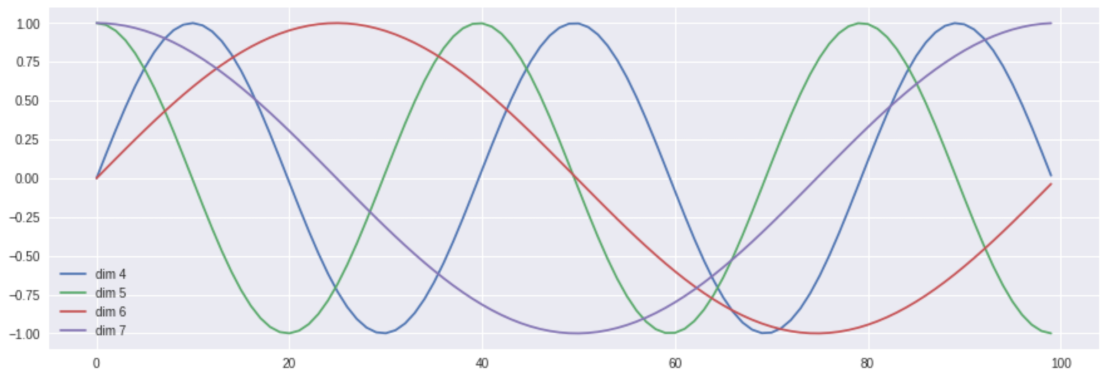
这种方法的优点是:
- 可以扩展到未知的序列长度。例如:当我们的模型需要翻译一个句子,而这个句子的长度大于训练集中所有句子的长度,这时,这种位置编码的方法也可以生成这个长度的位置编码向量。因为位置编码是基于数学公式生成的,而不是训练学来的,所以即使遇到训练时没见过的位置,也能生成合理的位置向量。
- 能编码相对位置信息:位置
的编码可以表示为位置 的编码的线性组合(三角函数加法公式) - 值域稳定:
1 | def position_embedding(seq_len, d_model): # -> (seq_len,d_model) |
Encoder-Decoder
Encoder: 输入是一个序列的 token 表示,通常使用词嵌入(word embeddings)来表示每个 token。这些嵌入被加上位置编码(position encodings)以表示它们在序列中的位置。Encoder 的输出是经过一系列自注意力层和前馈神经网络层处理后的编码表示。
Decoder 的输入也是一个序列的 token 表示,类似于 Encoder,它也使用词嵌入或者子词嵌入来表示每个 token,并加上位置编码。但是,Decoder 还接收来自 Encoder 的编码表示作为额外的输入,以帮助生成输出序列(如在翻译任务中,Encoder 输入的是一种语言下的文本序列,Decoder 输出的就是另外一种语言下的序列)。Decoder 的输出是经过一系列自注意力层、编码-解码注意力层和前馈神经网络层处理后的表示,通常用于生成目标序列的 token。
Encoder
Encoder 由 N 个相同的层组成,每个层又分为两个 sub-layer:
- 多头注意力
- 前馈神经网络
Encoder 的作用是将输入的文本序列转化为其潜在表征,Decoder 的作用是将 Encoder 输出的潜在表征转化为目标文本序列。
Multi-head Attention
在输入 X 的 Embeding 后,会分别乘以
多头注意力是注意力机制的一个变种。传统的单头注意力机制在输入 Q (
对于点积注意机制,也就是:
除以
Note
随着维度
- 假设
和 是独立且均值为 0、方差为 1 的向量。 - 那么
的期望是 0,方差是 。
通过乘以
由于 QKV 都是矩阵,所以
然而,单头注意力的空间表示有限,多头注意力机制允许模型同时关注来自不同位置的不同表示子空间的信息,如果只有一个注意力头,向量的表示能力会下降。具体来说,在多头注意力机制拿到 Q K V 后,它并不直接计算点积,而是先将 Q K V 分别经过一个的线性全连接层后,再分解为
这个步骤相当于我们希望线性全连接层能够将 Q K V 映射至
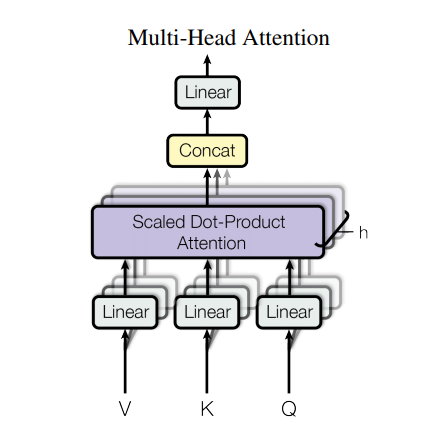
注意并不是将同一个 Q K V 映射 h 遍,而是直接通过一次的线性映射再分成 h 块
1 | def attention(query, key, value, mask=None, dropout=None): |
Add & Norm
Add 即 ResNet 中的“短接”(Shortcut Connection),将一个子层的输出及其输入加起来再交给下一个子层。
Norm 是指 Layer Normalization。对于一批输入的数据(batch_size x dim),对每一行(每个样本)做标准化,把每一行都变成均值为 0 方差为 1 的向量。对于文本序列,其输入是三维的 (batch_size x seq(n) x embedding dim(d)),也同样是取每个样本(1 x seq x embedding dim)做标准化。Transformer 使用 Layer Norm 的原因在于对于文本样本,其每个样本的长度是不确定的,所以会在有些样本的最后填充 0,进而影响 Batch Norm 的效果 (batch_sze x seq x 1)。因为当样本长度差值比较大的时候,Batch Norm 的切片方式计算出来的均值和方差抖动比较大。
1 | class LayerNorm(nn.Module): |
Position-wise FFN
就是一个简单的 MLP 网络,但是它是作用在每一个位置(也就是每个单词)上的,同一个 MLP,分别作用于每一个位置,所以其输入是
1 | class PositionwiseFeedForward(nn.Module): |
实际计算上,就是对最后两维做 MLP,所以在实现上只需要直接输入一个 MLP 并得到输出即可,Pytorch 会默认在最后两个维度进行 MLP。
FFN 的作用是对每个位置上的向量做独立的非线性变换,增强模型的表示能力,使得每个 token 的表示能够通过非线性投影捕捉更复杂的特征。
Decoder
Input & Output
训练阶段:
- Decoder 的输入是 完整的目标序列的前缀,例如,如果目标是
y = [<S>, y₁, y₂, y₃, y₄. <E>],那训练时 decoder 输入是左移版本([<S>, y₁, y₂, y₃]) 来预测[y₂, y₃, y₄, <E>]],输入和输出的长度是一样的 - 训练阶段为了防止模型看到后面的词,使用 masked self-attention,只允许每个位置看自己和前面的词。
- 所有输出可以并行生成,即每个位置可以一起训练。
推理阶段:
- Decoder 没有目标序列可用,只能一步一步生成。
- 初始只输入
[<BOS>](开始符),生成y₁; - 然后再输入
[<BOS>, y₁],生成y₂,依此类推。 - 因此,推理是自回归的(auto-regressive),不能并行生成,只能一步一步生成每个 token,每次在取出的序列中取最后一个加入输入序列。
Masked Multi-head Attention
在训练的时候,一个句子输入到模型中,我们会让模型逐个预测这个句子的每个词
比如 I am a student
我们会一次性让模型预测 am, a, student, 以此提高样本的利用效率。所以,我们在计算注意力机制的时候,我们并不希望在计算 I 的下一个单词的时候,就知道
在预测 I 的下一列时,只给出 I 的这一列作为上下文信息,并给模型预测下一个词。一般将要遮蔽的元素在 softmax 前设置为
| K Q | I | am | a | teacher |
|---|---|---|---|---|
| I | ||||
| am | x | |||
| a | x | x | ||
| teacher | x | x | x |
Cross Attention
Decoder 的第一层 Self-Attention 是为了理解自身已生成的序列,而 第二层 Cross-Attention 才是为了引入 Encoder 的外部上下文信息来辅助预测。解码器的第二块的KV来自于编码器。
Cross-Attention 使用三个矩阵:Decoder当前输入表示为
Encoder 输出的每个 token 向量本身同时携带其语义内容(V)和其可被匹配的语义特征(K),虽然初始输入一样,但 Transformer 中的注意力机制通常会对 K、V 各自做一次线性变换,通过不同的投影矩阵
Linear & Softmax
Decoder通过所有块后输出
Training Process
Transformer 训练的目标是通过对源序列与目标序列的学习,生成目标序列。
训练过程中,模型对数据的处理过程如下,大体可分为 6 个步骤:
- 在送入第一个编码器之前,输入序列首先被转换为嵌入(带有位置编码),产生词嵌入表示之后送入第一个编码器;
- 由各编码器组成的编码器堆栈按照顺序对第一步中的输出进行处理,产生输入序列的编码表示;
- 在右侧的解码器堆栈中,目标序列首先加一个句首标记,被转换成嵌入(带位置编码),产生词嵌入表示,之后送入第一个解码器;
- 由各解码器组成的解码器堆栈,将第三步的词嵌入表示,与编码器生成的潜在表示一起处理(用作 Q K),产生目标序列的解码表示;
- 输出层将其转换为词概率和最终的输出序列;
- 损失函数将这个输出序列与训练数据中的目标序列进行比较。这个损失被用来产生梯度,在反向传播过程中训练模型。
Inference Process
推理过程中的数据流转如下:
- 第一步与训练过程相同:输入序列首先被转换为嵌入(带有位置编码),产生词嵌入表示,之后送入第一个编码器。
- 第二步也与训练过程相同:由各编码器组成的编码器堆栈按照顺序对第一步中的输出进行处理,产生输入序列的编码表示。
- 从第三步开始变得不一样了:在第一个时间步,使用一个只有句首符号的空序列转换为嵌入(带有位置编码),并被送入解码器。
- 由各解码器组成的解码器堆栈,将第三步的空序列嵌入与编码器的输出一起处理,产生目标序列第一个词的解码表示。
- 输出层将其转换为词概率和第一个目标单词。
- 将这一步产生的目标单词填入解码器输入的序列中的第二个时间步位置。在第二个时间步,解码器输入序列包含句首符号产生的 token 和第一个时间步产生的目标单词。
- 回到第 3 个步骤,与之前一样,将新的解码器序列输入模型。然后取输出的第二个词并将其附加到解码器序列中。重复这个步骤,直到它预测出一个句末标记。需要明确的是,由于编码器序列在每次迭代中都不会改变,我们不必每次都重复第 1 和第 2 步。
Detail
Self Attention
编码器在计算 Q K V 的时候,直接使用源序列作为输入。
解码器块在计算第一个 Q K V 的时候,直接使用目标序列作为输入。
Padding and Padding Mask
文本序列不定长,所以需要将其填充到相同的长度,这个填充操作即为 Padding。
由于 Padding 是没有意义的,所以我们并不希望 Attention 将 Padding 看做单词来计算。所以除了 Masked Multi-head Attention 之外,我们还需要为 Padding 添加一个 Mask,这个 Mask 用来指示当前序列中 Padding 的位置。
1 | def attention(query, key, value, mask=None, dropout=None): |
Label Smoothing
Label Smoothing 是一种正则化手段,它可以避免 One-hot 编码那样让交叉熵函数走向极端。
当模型输出并经过 Softmax 后,会形成一个对词汇库内的所有词的概率。而如果此时我们将正确答案使用独热编码,那在计算的时候,其它词的概率会因为乘以 0 而被忽略,只有正确的词影响到最终的交叉熵。这会导致模型过分注重此时的正确词汇,进而导致模型的过拟合。
Label Smoothing 在编码正确答案的时候,并不使用 one-hot 编码,而是将正确答案的概率设定为
由于标签平滑的存在,如果模型对于某个单词特别有信心,输出特别大的概率,反而会提高损失。因为它使得其它单词的概率变得很小,进而与标签平滑后生成目标分布差异增加。
Parallel Training
Transformer 的训练是非常高效的,因为当我们给定一个输入序列和一个输出序列的时候,这些数据只需要通过模型一次就可以完成多次计算。
考虑两个序列:
- 源序列:
I am a student - 目标序列:
我是学生
在 Encoder 对源序列生成潜在表征时,其输出一个张量
- I
- I am
- I am a
以上三种情况下,后面一个单词蕴含的上下文信息。在经过解码器后,解码器会同时输出以上三种情况下的下一个单词,并一次性计算损失,因此其训练十分高效。
参考资料
- datawhalechina/learn-nlp-with-transformers: we want to create a repo to illustrate usage of transformers in chinese (github.com)
- 如何最简单、通俗地理解Transformer? - 知乎 (zhihu.com)
- Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili
- 【官方双语】GPT是什么?直观解释Transformer | 深度学习第5章_哔哩哔哩_bilibili
- 【官方双语】直观解释注意力机制,Transformer的核心 | 【深度学习第6章】_哔哩哔哩_bilibili
- The Annotated Transformer (harvard.edu)
- Attention is All you Need (nips.cc)