Vision Transformer
Transformer 引到 CV 的难度
在做自注意力机制的时候,是两两计算的,NLP 序列长度一般是几百上千,但如果把图片也当做序列的话,计算复杂度太高。一般来说分类任务是 224 x 224 = 50176。
已有的工作是想办法降低序列难度,比如:
- 用特征图来当 Transformer 的输入
- Stand-alone Attention 孤立注意力:用图片局部的窗口
- Axis Attention 轴自注意力:现在高度 Dimension 做一次自注意力,再在宽度上做以此 Dimension。
虽然这些工作也用了注意力机制,但是并不完全使用 Transformer,导致其无法用于大模型的训练。
Vision Transformer
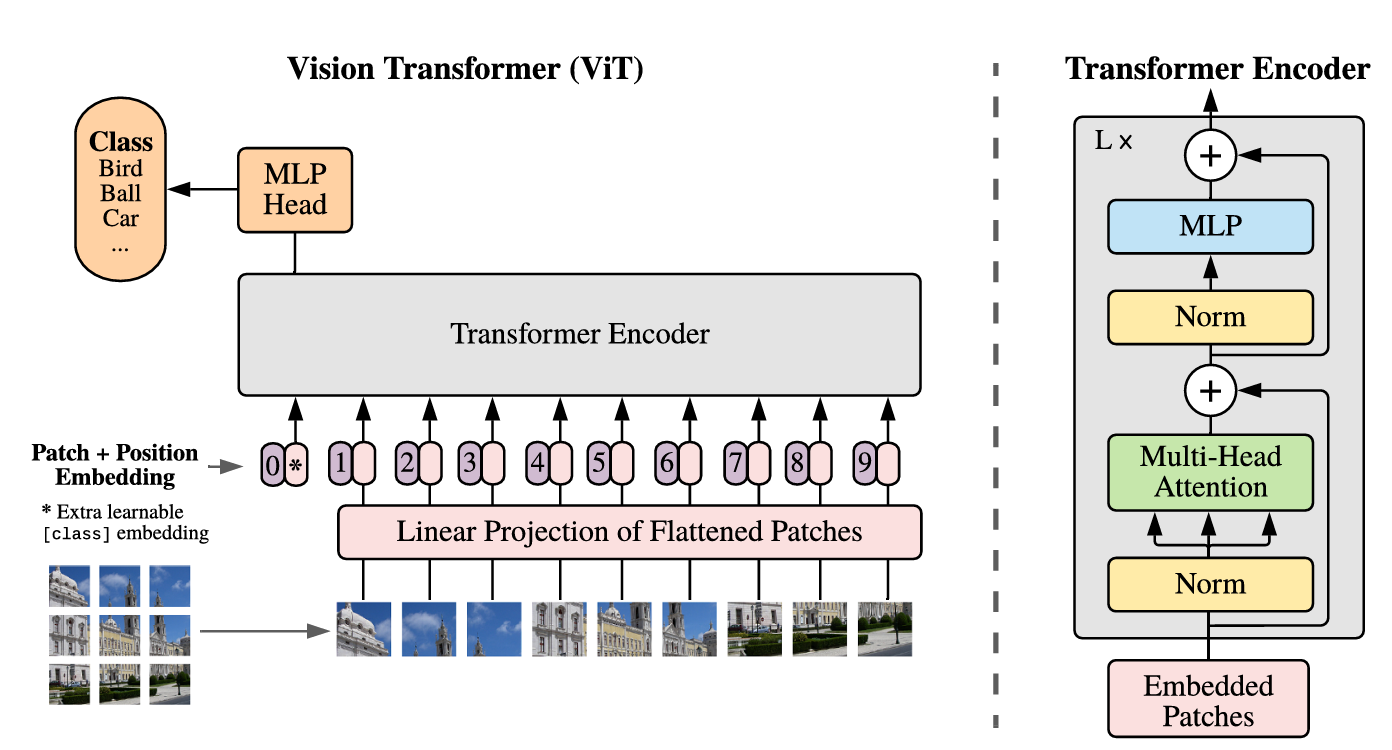
将图片分成多个 Patch,比如一张图片是 224 x 224,以 16 x 16 的 Patch 划分的话,就会变成 14 x 14,序列长度降低为 196。再将这些 Patch 当做是 NLP 中的单词,再用有监督的方式来训练。这种方法之前已经有人提过,但 ViT 第一次在大规模的数据上训练,并证明其结果非常好。

在中等大小的数据集上,ViT 弱于传统的 CNN,作者归因于 CNN 拥有更多地 Inductive Biases 归纳偏置,使得 CNN 拥有更多的先验信息。CNN 的归纳偏置主要有:
- Locality。相邻的图像区域有相似的特征。
- Translation Equivariance。平移等变性。先平移再卷积还是先卷积再平移结果是一样的。
ViT 实验的数据集上有更好的结果:
- ImageNet 22K 数据集 14 Millions
- Google JFT 300 Millions
训练过程:
- X: 224x224x3
- Patch Size = 16, 得到 196 个 Patch,每个 Patch 的大小为 16x16x3=768
- 获得 196 x 768 的图像 Patch,输入 768 x 768(
) 的线性投射层( ), 会随着图像的增大而变得更大,但前者是通过图像的 16 x 16 patch 得到的,是不变的。 - 线性投射层输出 196 x 768 的 Patch Embedding,再根据其在图片中的位置,sum位置编码(用向量表示其位置),再concat表示标签信息的 cls token,一起输入 Transformer Encoder
- 在 Transformer Encoder 的输出的 cls token 位置取出做 MLP 得到分类结果
论文实验:论文的实验结果表明,在 ImageNet 1.2 M 的数据集上,其结果比不过 ResNet,作者归因于是缺少归纳偏置,导致其需要更多信息来推导出归纳便宜。在 ImageNet 14
Transformer vs CNN
- Transformer 相比 CNN 缺少归纳偏置,所以往往需要更多的数据来进行训练,或者在大规模的数据集上进行预训练,比如在 ImageNet 上直接训练和先在JFT数据集(3亿)上训练会相差 13% 的准确率;
- 已经有文献在理论上指出自注意机制在理论上比卷积操作更加灵活地编码了局部特征;
- 实验上足够参数的多头注意力机制相比卷积是一种更加通用的操作,可以将卷积视为其的一种特殊情况;
- CNN 的滤波器大小对于所有的输入是不变的,而自注意力机制不仅关注局部特征,而且关注全局特征,相当于可以自适应地调整滤波器的核权重(kernel weights)和感受野(receptive field)(类似于 Deformable Convolutional Networks);
- CNN 会同时进行特征聚合和转换,而 Transformer 中这两步是解耦的,自注意力机制进行特征聚合,前馈神经网络进行特征转换;
SSL (Self-Supervised Learning)
Transformer 往往需要现在大规模的数据集上进行预训练,然而,对这些数据集进行标注是困难的,所以预训练常常采用自监督的方法。可以分为两类:
-
Fill in the blanks:让模型去预测图片中被遮挡的区域,或者视频帧序列中前后的帧。
-
Contrastive learning:一种自监督学习的方法,它的核心思想是通过将相似的样本拉近、不同的样本推远来学习有用的特征表示。具体实施上,就是先对图片进行扰动( nuisance transformations),扰动分为两种:
-
Nuisance Transformations with Minor Semantic Changes 会改变图像语义信息的。如在相同场景中替换对象,使用微小的对抗性扰动来改变图像类别;
-
Nuisance Transformations without Semantic Changes 不会改变图像语义信息的。如旋转、裁剪、风格化等;
对于不改变语义的无关变换,样本之间的相似性应最大化。对于可能改变语义的轻微变化,样本之间的相似性应降低或最小化。
在自监督预训练阶段,进行什么样的任务(pretext task)是重要的选择,主要分为:
- 生成任务 generative:如生成遮蔽图像、图像上色、基于GAN的方法等;
- 基于上下文 context-based:利用图像的 patches 之间的联系,或者是视频帧之间的联系;如拼图游戏、遮蔽对象分类、预测所进行的几何变换;
- 跨模态 cross-modal:使用多种数据模态,如图像和文字、音频和视频等。