On the Robustness of Vision Transformers to Adversarial Examples
On the Robustness of Vision Transformers to Adversarial Examples
On the Robustness of Vision Transformers to Adversarial Examples
Mahmood et.al.
1 | @InProceedings{Mahmood_2021_ICCV, |
- 在 ViT 上测试了标准的 6 种白盒和 2 种黑盒攻击;
- 研究了攻击的可转移性,并发现 CNN 和 Transformer 之间的转移没那么简单;
- 分析了一个关于 CNN 和 ViT 的简单的集成防御(ensemble defense),并创建了一种新的攻击方法,来说明这样的防御在白盒对抗攻击中是不安全的;在黑盒攻击下,可以在不牺牲准确率的前提下达到前所未有的鲁棒性
白盒攻击测试
方法:
-
FGSM(Fast Gradient Sign Method):Goodfellow 等人提出。对抗攻击中的无目标攻击,目标是通过计算梯度来提供改变图片的方向,进而使得损失函数最大化。
其中
是模型的参数, 是输入样本, 是模型的输出。 是步长,也就是朝着梯度的方法走多长。 -
MIM(Momentum Iterative Method):在 FGSM 的基础上,加入了动量,也就是对于第
次的梯度计算 ,考虑第 次的梯度大小。 -
PGD( Projected Gradient Descent)
-
APGD(Auto Projected Gradient Descent )
-
Carlini and Wagner (C & W) attack
-
BPDA(Backward Pass Differentiable Approximation)
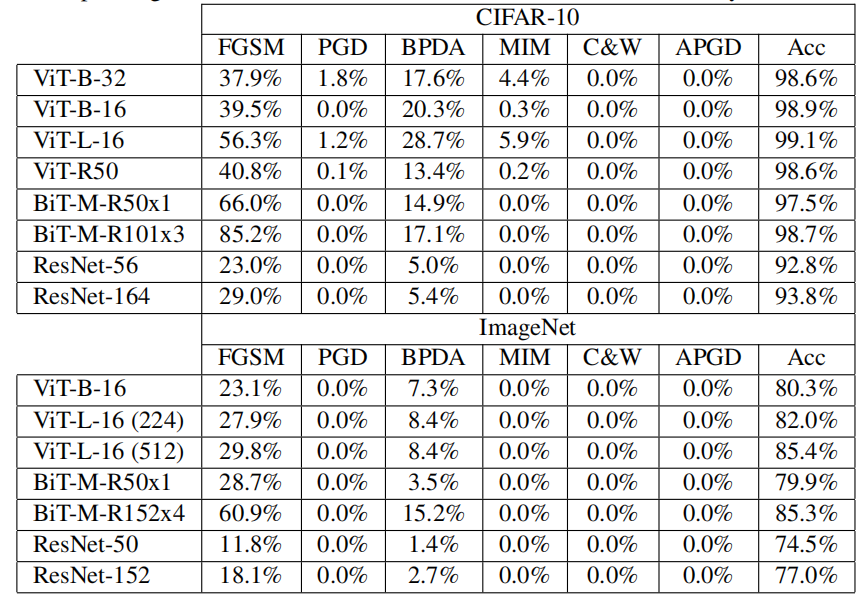
模型选择上跨越了多个不同的规模、不同的架构,包括 ViT、BiT、CNN(ResNet)。**实验结果上说明了 ViT 没有提供额外的对抗鲁棒性。**尤其是在面对 C&W 和 APGD 攻击的时候,鲁棒性为 0%。
下图即为鲁棒性的实验结果。采用无穷范数
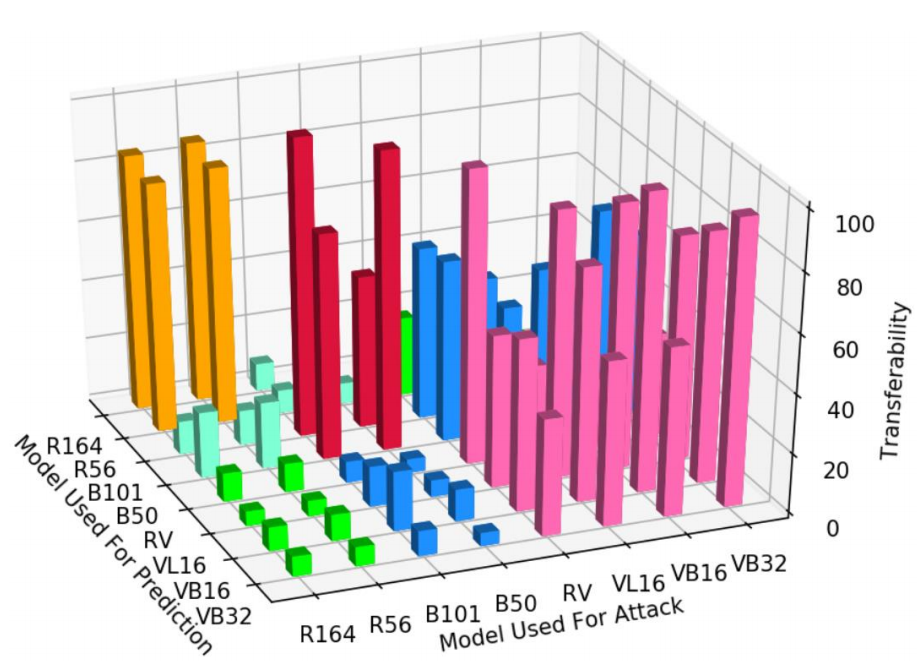
可转移性测试
绿色、蓝色、亮蓝色是不同类别模的模型之间的迁移。
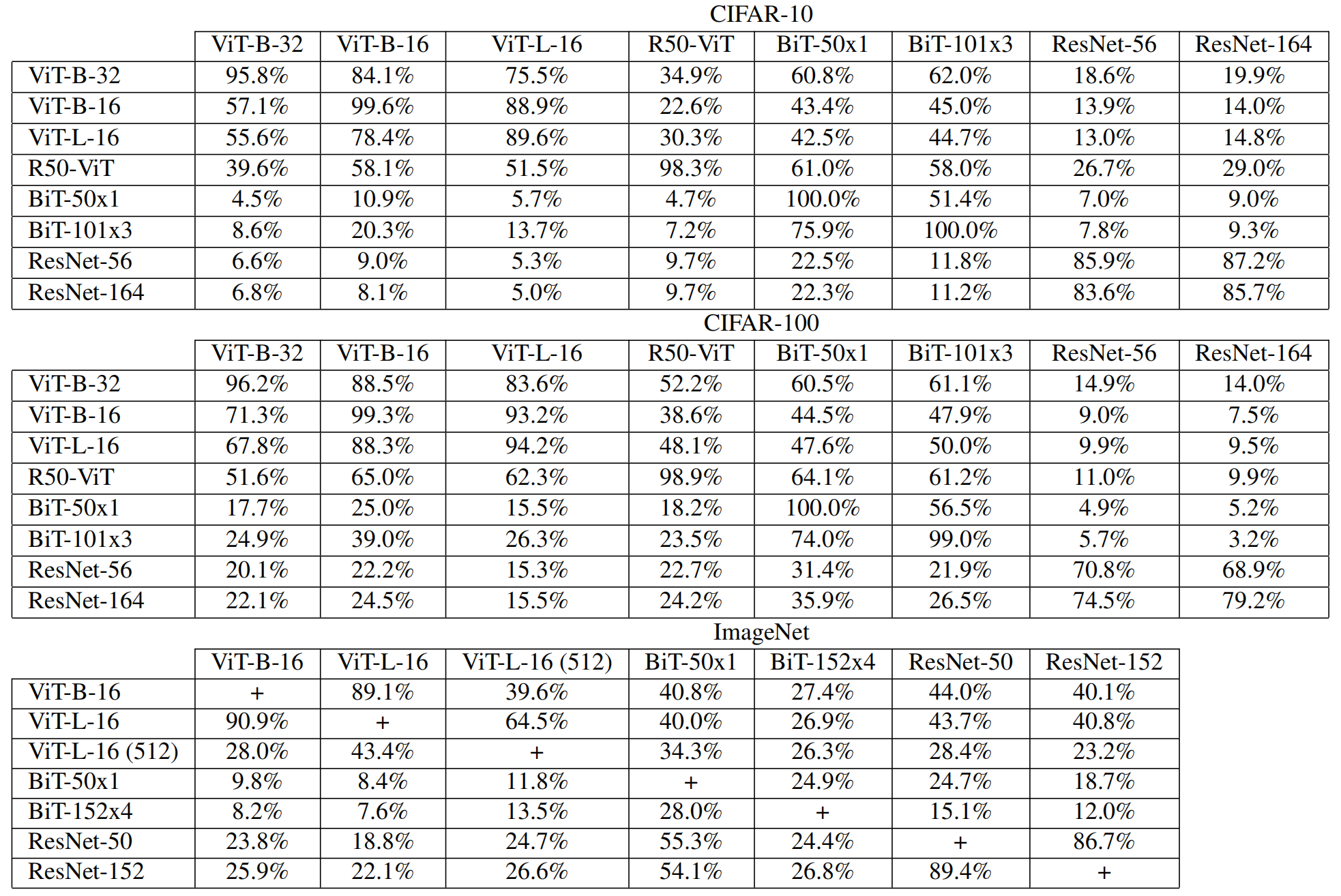
实验结果:
- MIM、PGD、FGSM 的可转移性最高;
- ViT、BiT 和 ResNet 三者之间不同类别的模型的可转移性非常低;
集成防御
根据不同类别之间的模型的可转移性非常低的性质,我们可以使用至少两个类别的模型来形成集成防御。
由于 ResNet 的精度较低,所以不采用 ResNet。采用 ViT 和 BiT 来作为集成防御。
三种常见的方法:
- Majority voting:所有分类器都进行预测,采用被预测得最多的类别作为输出。缺点是需要所有模型都得出结果,代价较大;
- Absolute consensus:如果分类器之间的结果不一致,则直接标记为对抗样本。缺点是容易误判 clean samples;
- Random selection:随机采用一个模型来预测,并用其结果作为最终结果。
论文采用 RS 作为集成防御,可以看到攻击的成功率从 100% 降低到了 63.15%。然而,这是因为论文只采用其中一个模型生成对抗样本。论文提出了一个新的攻击方法,来攻击这种集成防御的情况,
针对集成防御的攻击方法:SAGA
Self-Attention Gradient Attack
SAGA 的目标是同时对多个模型发起攻击。
-
K 是 CNN 模型的集合,
表示的是对于每个 CNN 模型的梯度设置的权重; -
同理,
是 ViT 模型的集合, 表示的是对于每个 ViT 模型的梯度设置的权重; -
是 self-attention map,也就是模型对于 x 的全局注意力 是每一层的注意力头数; 是自注意力的层数; 是每个头(i)和层(l)的注意力权重矩阵; 是单位矩阵
Attention Map 计算的是输入中的各个元素在模型中的“重要性”,可以用热力图来可视化表示。在这里,
表示的是注意力权重的平滑,避免最终的计算结果偏向于某个头。在每个头都平滑后,将所有头相加作为这个自注意力层的权重,再和所有层的自注意力权重相乘,来得到累积后的注意权重,最后和 逐元素相乘来得到最终的注意力图。 在这个攻击方法中,
的作用就是为攻击 ViT 的时候考虑输入的注意力权重,对权重高的元素施加更多的梯度干扰。
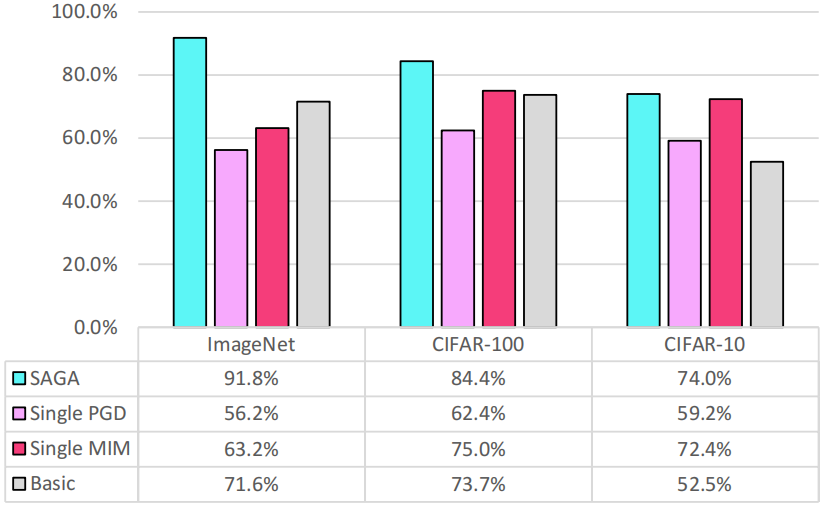
其中的 Basic 表示的是直接组合集成的所有模型的梯度,不考虑权重和自注意力。
黑盒模型安全性和可转移性
前文所提到的脆弱性是因为白盒的设置,所以集成防御方法失效。本文考虑在黑盒设置下的安全性,考虑以下方法:
-
RayS attack:query-based,不断查询模型并更新噪声。对噪声进行不同方向上的二分查询,如果一个方向上无论如何查询都不能在
下攻击成功,则换一个方向,直到成功或达到查询上限为止,最终会找到最佳的攻击方向 和最佳的攻击半径 ,本质上是寻找模型的决策边界; 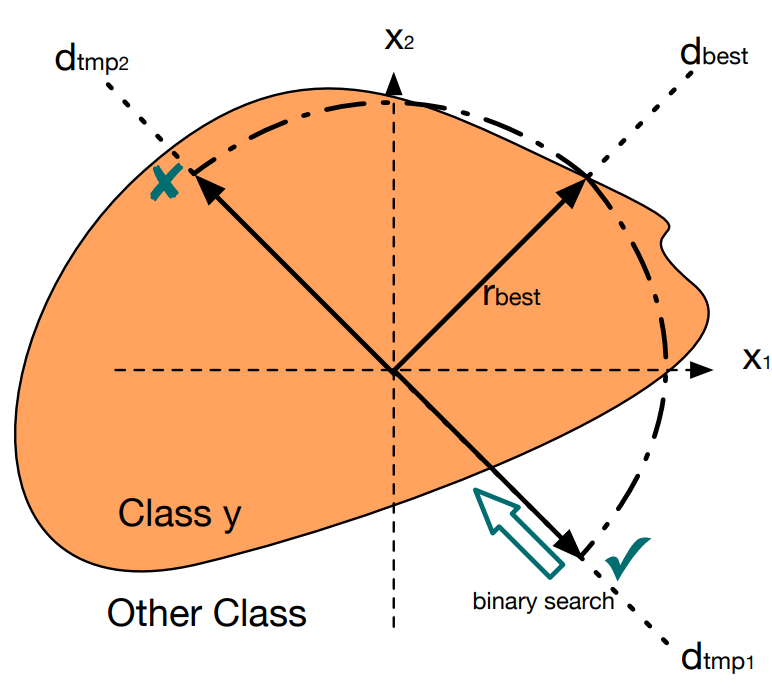
-
Adaptive Black-Box Attack:transfer attack,攻击者可以访问一部分的训练数据和查询模型。通过查询训练数据来获取标签,进而训练一个分类器,攻击训练的分类器后再攻击目标。
实验结果(表格的第一列表示的是模型的组合,即 ViT/BiT 表示 ViT 和 BiT 的集成,其余两个是单独的模型),数值表示对于对抗样本分类的正确率,数值越高,分类效果越好:
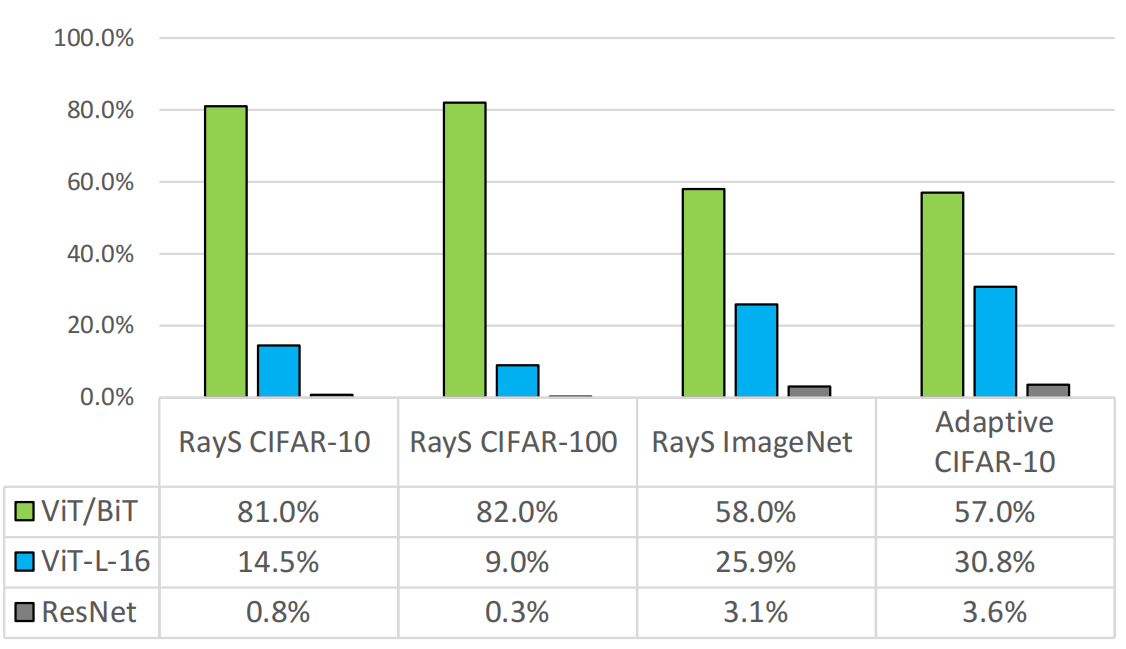
实验结果表明,简单的跨模型类别的集成就可以很好地防御这些黑盒攻击。在能够得到 100% 的训练数据下的 Adaptive 的攻击成功率要高于 RayS,但仍然保持在不高的水平。
而且,这种鲁棒性的提升并不以牺牲准确性为代价,因为其利用的是跨模型类别的攻击可转移性较低,而不影响其中某个模型的准确率,这两者的准确率都很高从而使得集成防御下也保持了这种准确率。其在干净样本下的准确率为:
| Dataset | Accuracy |
|---|---|
| CIFAR-10 | 98.2% |
| CIFAR-100 | 92.83% |
| ImageNet | 85.37% |
其它
一些术语
BiT-M: 论文 “Big transfer (bit): General visual representation learning” 中的方法。使用大规模的数据集先训练,再用小数据集微调的 CNN。
ViT-B-32:B 代表模型结构的复杂性,B 为 12 层,L 为 24 层。32 代表 patch size。
句式
This puts transformers in the unique position of being a promising alternative to traditional convolutional neural networks (CNNs).
这使得 xxx 处于作为 xxx 的一个有前途的替代品的独特位置。
Transferability refers to the fact that adversarial examples crafted to fool one CNN are often misclassified by other CNNs as well.
一句话介绍 Transferability。
We investigate how the advent of Vision Transformers advance the field of adversarial machine learning.
我们研究了 ViT 的出线是如何推进对抗机器学习领域的。
We then break our analysis of Vision Transformers into several related questions: …
将我们的分析拆为…
However, this is not the case as the adversarial examples we are using only come from attacking one model.
然而,事实并非如此,因为…
单词
unprecedented 前所未有的
genusu 属、类别