When Adversarial Training Meets Vision Transformers
When Adversarial Training Meets Vision Transformers: Recipes from Training to Architecture
Yichuan Mo et.al.
北京大学
NIPS 2022
Github: 📁
1 | @inproceedings{mo2022when, |
- 研究了多重对抗训练技术在 ViT 上的表现;
- 发现了预训练以及 SGD 优化器对于 ViT 的对抗训练是必须的;
- 从 ViT 的独特架构下研究了其对抗鲁棒性;
- 发现了随机遮蔽一些注意模块的梯度或者遮蔽对一些 patch 的干扰可以显著提高其对抗鲁棒性。
ViT 的对抗训练的影响因素
在训练的过程中不断生成新的对抗样本,并用对抗样本加入训练,循环往复。其目标是:
模型参数, 扰动 - 也就是在最小的变化参数
下,让加入扰动后能导致的对抗样本的预测标签与真实标签所能达到的最大差距尽可能小
本文所采用的数据集:CIFAR-10、Imagenette(ImageNet-1K 的 10 类别子集)
所采用的架构:ViT-B 和 Swin-B,在 ImageNet-1K 上预训练。
参数设置:无穷范数,
对抗样本生成:PGD-10,step_size=2/255
对抗训练:40 Epochs,SGD(weight decay 1e-4,lr 0.1,在 36 和 38 epoch 的时候除以 10)
Note
学习率调度策略可能是基于经验或之前的实验结果预设的。在很多实践中,使用分阶段的学习率衰减是有效的,例如,在训练的早期使用较大的学习率快速收敛,然后在中期和后期逐步降低学习率精细调整模型。
在训练过程中,可以通过观察损失函数的变化情况来确定何时降低学习率。如果在某个阶段发现损失函数下降变得很慢,甚至出现震荡,适当降低学习率是有益的。
一种常见的实现方法是使用学习率调度器(Learning Rate Scheduler)。例如,在PyTorch中,可以使用torch.optim.lr_scheduler模块中的各种调度器来实现这一目标。
1 | import torch.optim as optim |
评估对抗鲁棒性的攻击方法:20-step PGD,step_size=2/255 以及 AutoAttack
预训练对 ViT 对抗鲁棒性的影响
❓ ViT 的成功很大程度依赖于大规模数据集的预训练,这种预训练对于对抗鲁棒性的影响如何?
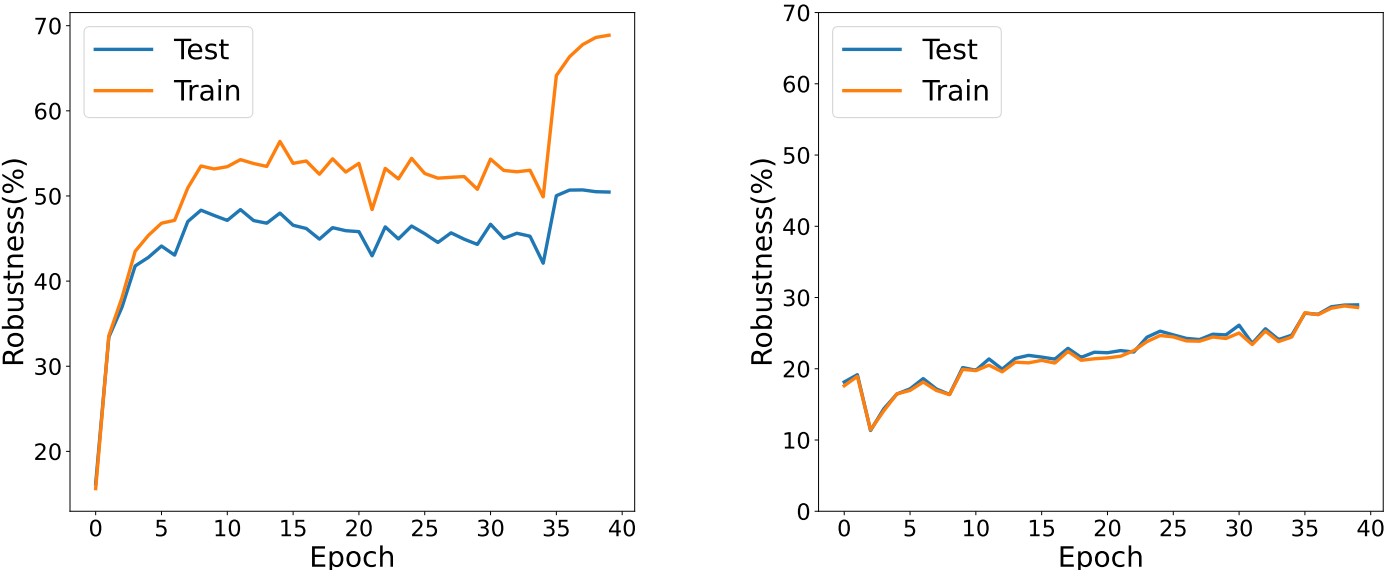
下图绘制了对抗训练过程中模型学习曲线(learning curve),左边是预训练下的学习曲线,右图是没有预训练(training from scratch)下的学习曲线。可以看到在没有预训练的情况下,鲁棒性一直保持着比较低的水平(30%),因为其对于训练数据的欠拟合影响了它的性能。预训练后再经过对抗训练鲁棒性能够提高 20%。
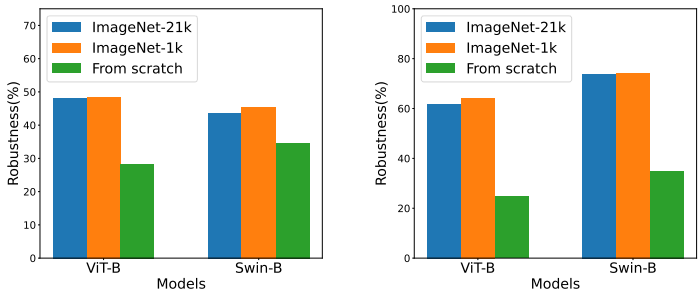
❓ 更大的预训练数据集是否可以带来更高的鲁棒性?
3 种预训练情况:ImageNet-21K ImageNet-1K 无预训练。下图展示了三种情况下的鲁棒性,可以看到 ImageNet-21K 虽然数据集更大,但是鲁棒性提升有限,甚至有点降低。
梯度裁剪的必要性
ViT 和 Swin 架构采取了 Gradient clipping,而 DeiT 则没有。
❓ 在对抗训练过程中,是否有必须采取梯度裁剪?
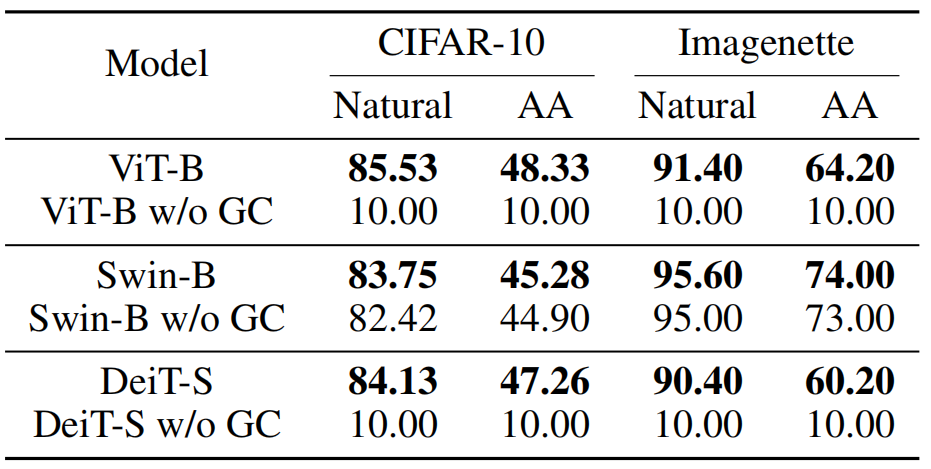
下图展示了在对抗训练后模型的表现,分为 Natural 和 AutoAttack 下的准确率。w/0 GC 表示没有梯度裁剪的情况。
-
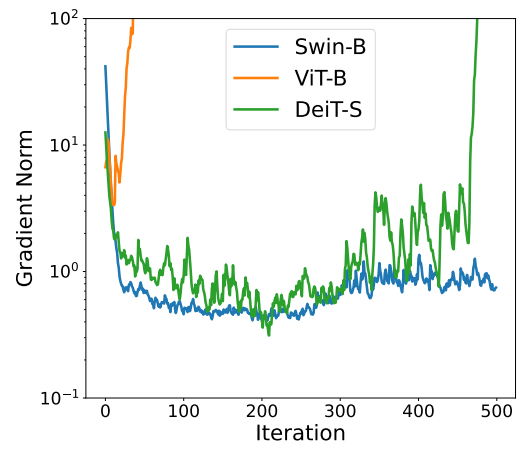
ViT 和 DeiT 在小数据集上、没有梯度裁剪的情况下,难以进行对抗性训练,导致准确率很低(10%),因为在开始训练不久就发生了梯度爆炸;
-
在以
的梯度裁剪下,ViT-B 和 DeiT-S 都可以提高小数据集下的对抗训练后的准确率; -
Swin 架构虽然加不加梯度裁剪都可以直接训练,但梯度裁剪后显然提高了它的准确率。
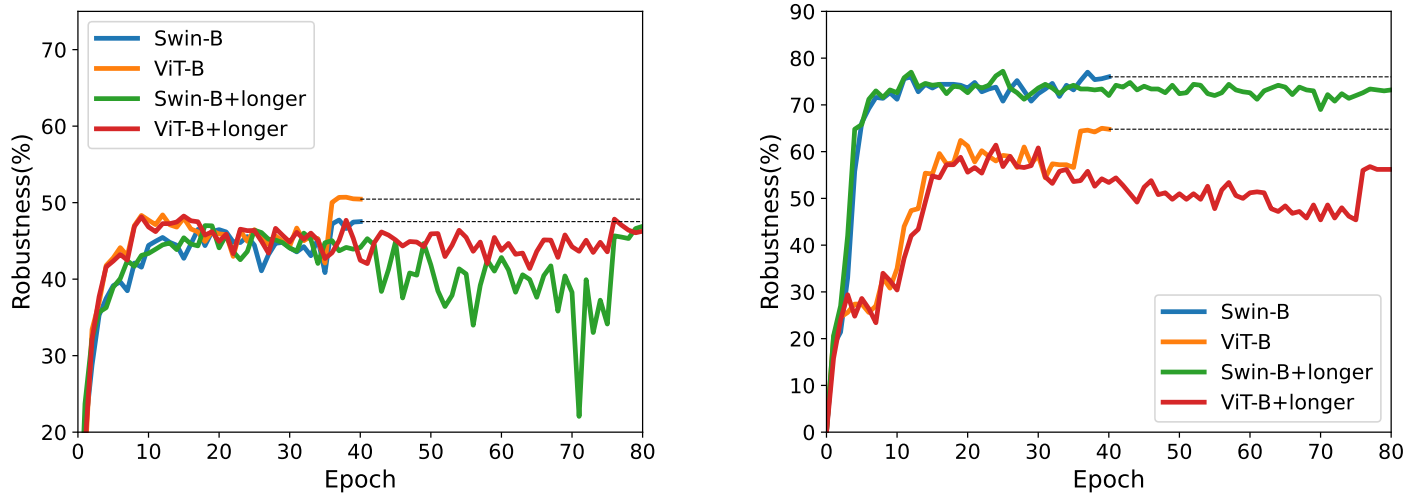
对抗训练 Epoch 的影响
Swin 在 ImageNet-1K 上需要训练 300 epochs,而 ResNet 只需要 90 epochs。ViT 一直被认为是需要更多地 epoch 训练的,而对抗训练下是否保持如此特性?
❓ 训练更多的 epoch 会不会提高其鲁棒性?
实验设置:40 和 80 epochs,并在 75 和 78 epoch 的时候降低学习率。在下图可以看到 40 epoch 的时候和 80 epoch 的时候的学习曲线。可以看到对于实验中的所有模型,Epoch 的提升都没有带来更佳的鲁棒性,甚至可能降低鲁棒性。
数据增强的影响
❓ 在对抗训练前对对抗样本应用数据增强,是否有可能提高最终模型的鲁棒性?
Mixup:通过线性插值来混合训练样本及其标签。拥有一定的正则化效果,但可能生成脱离自然数据分布的数据。
Randaugment:定义一组基础的数据增强操作,如旋转、平移、剪切、颜色变换等,每次从这些操作中随机选择若干个,并对训练样本应用这些操作。
CutMix:将两个训练样本的区域进行混合来生成新的训练样本。随机选择两个样本
下图中左边是 ViT-B 在 CIFAR-10 上的训练情况,右边是 Swin-B 在 Imagenette 上的训练情况。
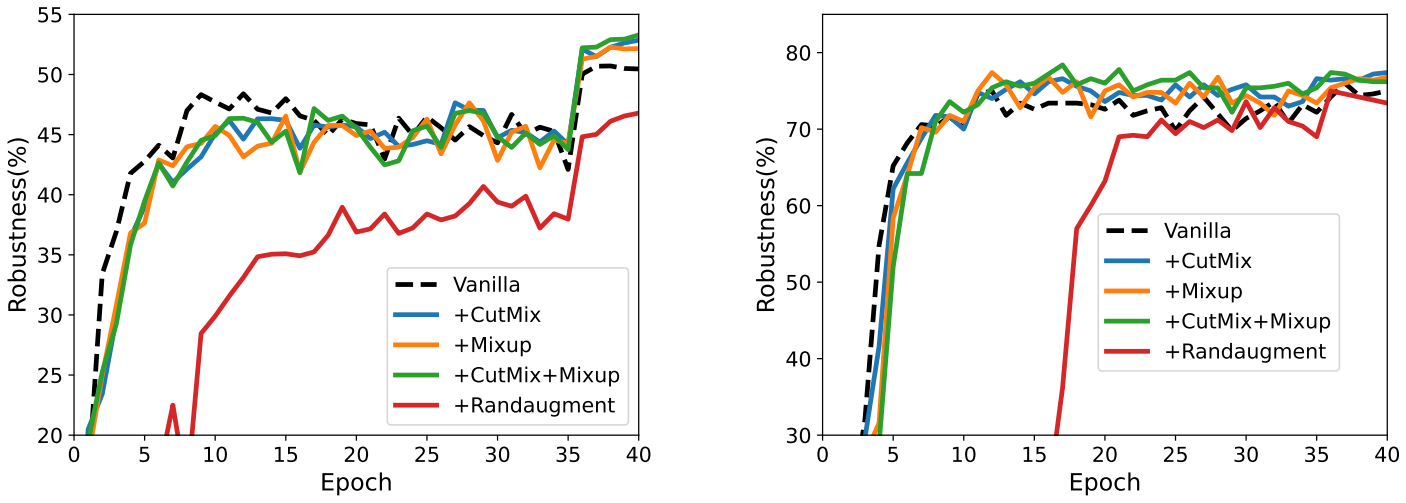
- CutMix 和 Mixup 可以为 ViT 和 Swin 提供更高的鲁棒性
- RandAugment 会降低它们的鲁棒性,可能是因为其对于模型来说太难了(那是否有可能通过继续训练来解决这种难度进而提高鲁棒性呢?)
优化器的影响
❓ 默认的 ViT 优化器是 AdamW,那 SGD 和 AdamW 的选择对对抗训练后的鲁棒性有影响吗?
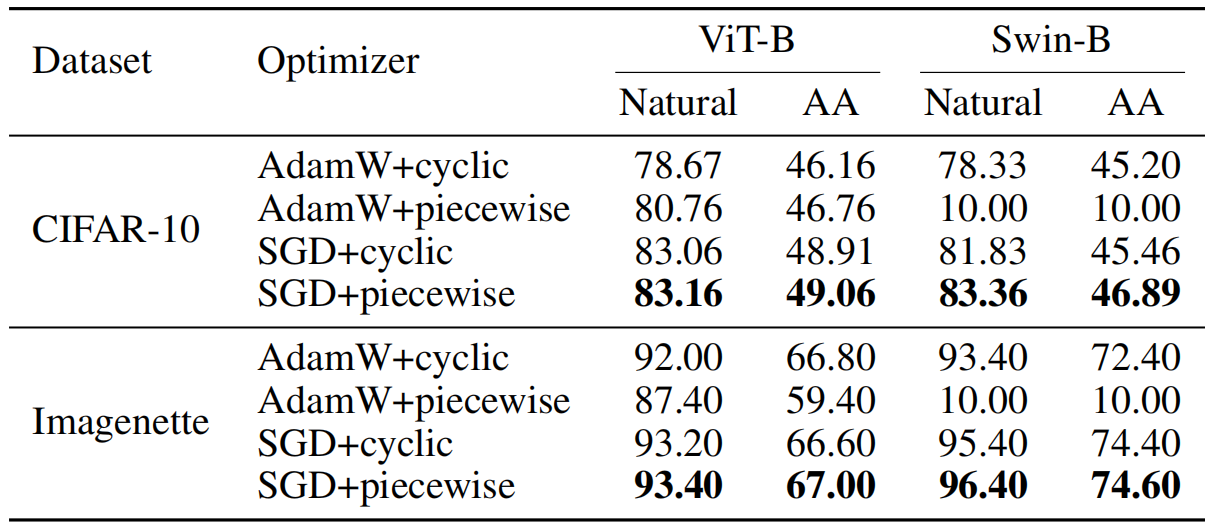
Cyclic Learning Rate 是一种动态调整学习率的方法,它在一个预定义的范围内循环变化。
Piecewise Learning Rate 是指将训练过程分成多个阶段,在每个阶段使用不同的固定学习率。通过在训练的不同阶段设置不同的学习率,可以更好地控制模型的训练过程,通常在达到一定的 epoch 后降低学习率。
实验结果表明,SGD 比 AdamW 更适合用于对抗训练,AdamW 适合用 Cyclic,SGD 适合用 Piecewise
对抗训练 Trick 总结
- 预训练和梯度裁剪是必须的
- 增加一些数据增强可能会有效,如 CutMix 和 Mixup
- 采用 SGD + piecewise 学习率调度
- 没必要采用比较多的轮数训练
架构角度下的 ViT 对抗鲁棒性
ViT 相比 CNN 在架构上完全不同,而且在表层就可以连接到整个图片中的信息。论文提出了两种对抗训练策略,这两个策略都是基于 ViT 的特性进行设计的。
Attention Random Dropping
ARD
论文将第 L 个块的输出形式化为:
表示多头注意力 表示 attention 后的 skip connection 表示 MLP 及其 skip connection
进而计算梯度的公式为:
第二个等号来自于
ARD 的形式化表达就是:
以 的概率取 0,(1-p) 的概率取 1 - 也就是有 p 的概率丢弃掉
可以继续计算得到损失函数在
在应用 ARD 在对抗训练中的时候,只将其作为 warming-up 策略,也就是经过一定阶段后,使用原来的方法继续训练。在 warming-up 阶段,p 从1 线性降低至 0。
Perturbation Random Masking
PRM。对于某个 patch 的干扰会以一定的概率 k 不作用。对于图片的总体计算就是随机生成一个掩码 M (总 patch 乘以 k 数量的 patch 被遮蔽)来遮蔽干扰。
这里干扰的生成方式用的 PGD。
PRM 一样作为 warming-up,线性减少遮蔽的 patch 数量。
ARD + PRM
实验
模型:ViT DeiT ConViT Swin
模型规模:base samll tiny
在前文提及的对抗训练下,用 CW-20 PGD-20 PGD-100 和 AA 来攻击模型,以此评估模型的鲁棒性
- 更大的 ViT 可以提高准确性和鲁棒性;
- 更好地架构(Swin)在高分辨率的数据集(ImageNet-1K)预训练后,其在小分辨率数据集上的对抗训练后的鲁棒性反而较低,作者归因于 Swin 中的归纳偏置在小分辨率图像上有所失效;
- ARD PRM 都可以提高准确率和鲁棒性。Swin on CIFAR-10:ARM+1.16% PRM+1.13%,两者都用 +1.29%
- 实验上也发现与 TRADES 和 MART 两个对抗训练方法相结合可以提高他们的表现;
- 超参数实验:
warming-up 的轮数对最终结果的影响。
其它
术语
AdamW: 一种优化器,基于 Adam,用来训练 ViT 的时候表现更佳。
Gradient Clipping: 梯度裁剪,防止梯度爆炸问题。通过设定一个阈值来限制梯度的大小。如果梯度超过这个阈值,它们将被缩放至阈值以内,从而避免了大的权重更新。
无穷范数:\Vert 打出来
model weight averaging:一种用于提升深度学习模型泛化能力的技术。通过平均多个训练过程中不同时间点的模型权重,可以获得一个性能更好的模型。这种方法可以减小过拟合的风险,并在验证集上表现得更稳健
TRADES: TRadeoff-inspired Adversarial DEfense via Surrogate-loss 对抗训练方法,核心思想是将标准训练误差与对抗训练误差分开,并通过引入一个权重参数来控制两者之间的平衡。对抗损失就是 KL 散度度量下的原始样本输出和对抗样本输出的差异。也就是明确地将损失函数分成对抗损失和分类损失
MART: Misclassification Aware adversarial Regularization with a Tightness 对抗训练方法
-
表示模型对于干净样本 在真实标签 y 上的预测概率 -
标准分类损失:模型在干净样本上的分类损失,通常使用交叉熵损失。
对抗分类损失:模型在对抗样本上的分类损失,通常使用交叉熵损失。
误分类惩罚项:针对容易被误分类的样本(也就是
小,进而使得该项系数变大),增加其损失权重。
句子
ViTs are shown to provide no more adversarial robustness than convolutional neural networks (CNNs).
说明 ViT 在对抗鲁棒性上相比卷积神经网络没有优势。
Based on large-scale pre-training, ViTs have achieved competitive and even better performance compared to CNNs in several fields such as semantic segmentation, object detection, and image generation.
说明 ViT 对于 CNN 在多种任务上的优势。
ViTs still demand adversarial training (adversarial training), an approach that incorporates adversarial examples into training and obtains notable empirical robustness.
一句话介绍了对抗性训练的过程及其好处。