Patch-fool: Are vision transformers always robust against adversarial perturbations?
Conclusion
ViT 的对抗鲁棒性并不总高于 CNN
每个 patch 的干扰像素的数量高度影响 ViT 和 CNN 之间的鲁棒性排名
提出了 Patch Fool 方法及其两个变种,总结就是对部分patch、patch 内的部分像素做干扰,在交叉熵损失函数后添加了一项用于提高所选patch对其它patch的注意力值的项
Related work
一些工作指出,在足够数量的数据集上训练的 ViT,在大部分的情况下至少与和它相对应的 ResNet 一样鲁棒,无论是在自然损坏、分布偏移还是对抗性干扰的场景中 [1]。在
[1] Bhojanapalli S, Chakrabarti A, Glasner D, et al. Understanding robustness of transformers for image classification[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 10231-10241.
[2] Aldahdooh, Ahmed, Wassim Hamidouche, and Olivier Deforges. “Reveal of vision transformers robustness against adversarial attacks.” arXiv preprint arXiv:2106.03734 (2021).
[3] Shao R, Shi Z, Yi J, et al. On the adversarial robustness of vision transformers[J]. arXiv preprint arXiv:2103.15670, 2021.
Patch Fool
Attack setup
符号:
- 由多个 patch 组成的图片
, 是 patch 的数量, 是每个 patch 的维度 - 对抗性干扰
- one hot vector
,只有第 个元素是 1 - 损失函数
攻击的目标是:
其中
根据 Attention 确定
用
论文中,将
Attention-aware Loss
为了最大化选定的 patch 的影响,论文选择用一个损失函数来最大化这个 patch 对其它 patch 的注意力,也就是在
将上面的损失与最大化分类差距的交叉熵
为了解决这两个损失的梯度冲突,论文使用了 PCGrad 来更新干扰,也就是对于
作者还进一步使用了 Adam 优化器来根据梯度确定更新
Variant
需要对 patch 中的多少像素做干扰才能可以?
- 只对很少的像素做干扰 (sparse patch fool)
- 对整个 patch 做干扰(前文所述的 patch fool)
Sparse patch fool 使用 mask
MILD Patch-Fool
为了符合
Experiments
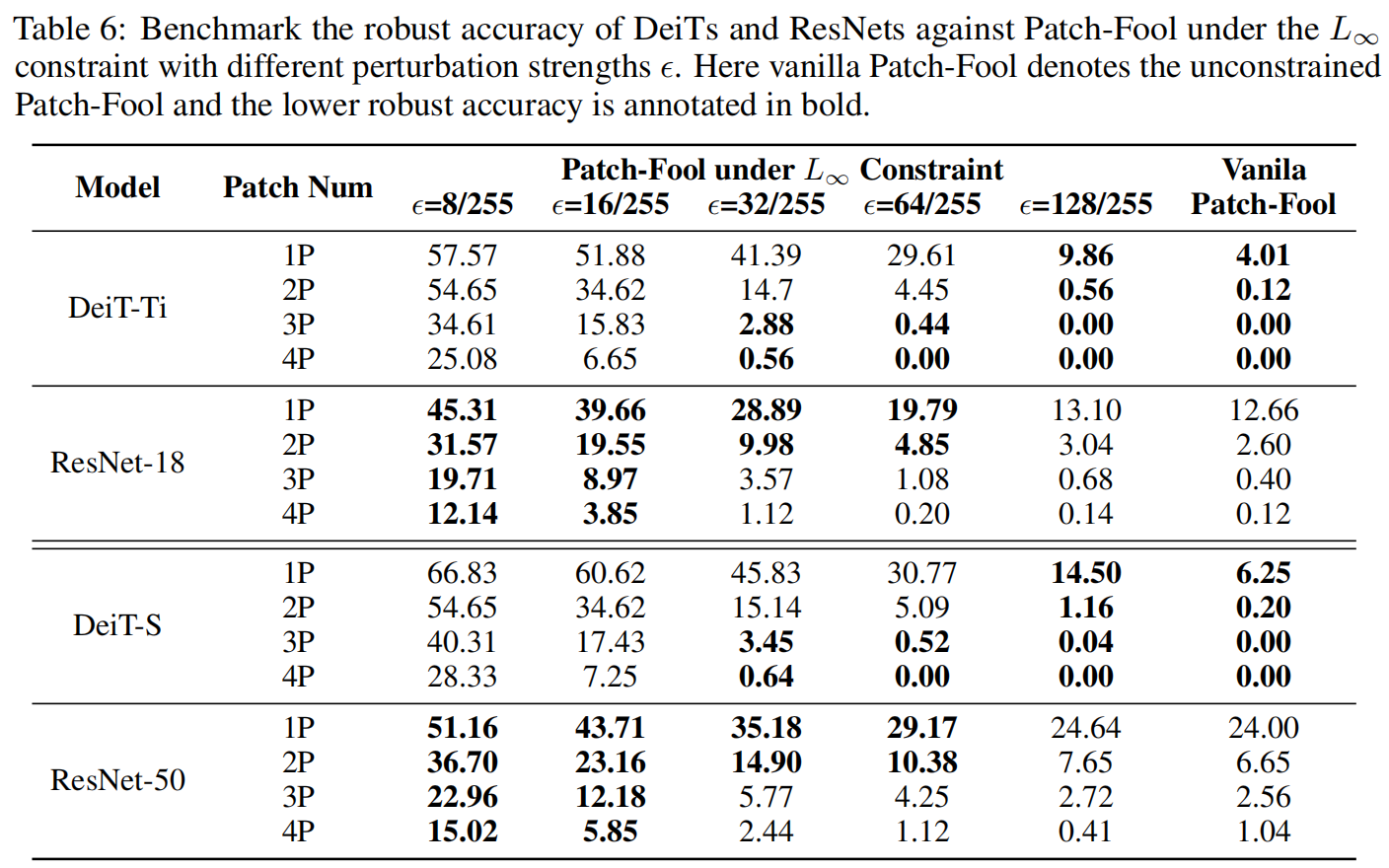
PR 为 patch 内干扰的像素比例,#Patch 为干扰的 patch 数量,指标是鲁班准确率。可以看到 DeiT 和 ResNet 在不同的 PR 和 #Patch 下的鲁棒性会有差异,没有谁恒优于谁。加粗的是比较差的。
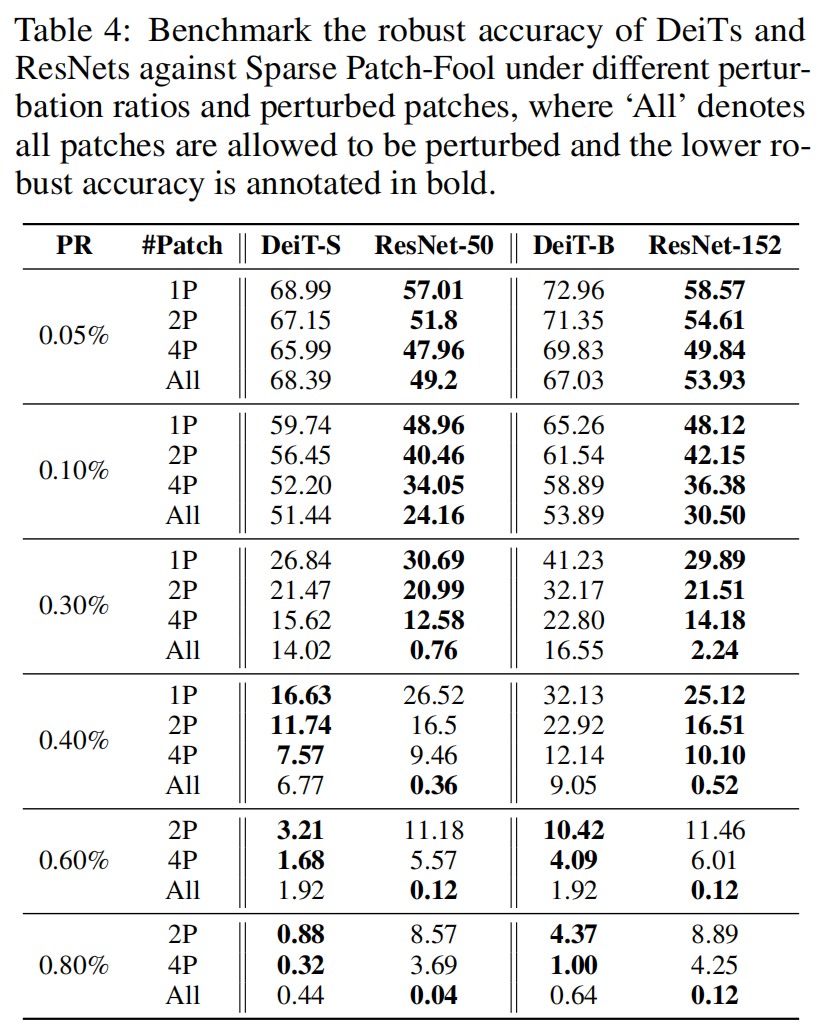
下面是