defforward(self, x): x = self.forward_features(x) ifself.head_dist isnotNone: x, x_dist = self.head(x[0]), self.head_dist(x[1]) # x must be a tuple ifself.training andnot torch.jit.is_scripting(): # during inference, return the average of both classifier predictions return x, x_dist else: return (x + x_dist) / 2 else: x = self.head(x) return x
defforward(self, x): B, N, C = x.shape qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
偏差项(bias)通常在神经网络中的线性变换中使用。它是一个与输入无关的可学习参数,加到线性变换的结果上。在注意力机制中,Query、Key 和 Value 向量是通过线性变换生成的(即:输入向量乘以权重矩阵),而偏差项就是这个过程中加到结果上的一部分。其目的是帮助模型在初始状态下避免对称性问题,使得每个神经元在初始时拥有不同的输出,即便输入是相同的,这有助于更好地训练网络。
defforward(self, x: Tuple[torch.Tensor, torch.Tensor]) -> Tuple[torch.Tensor, torch.Tensor]: # 先池化一遍,然后再经过 Transformer Blocks x, cls_tokens = x token_length = cls_tokens.shape[1] ifself.pool isnotNone: # Pool 内部对 x 进行池化,对 cls_token 进行线性映射 # x = self.conv(x) # cls_token = self.fc(cls_token) x, cls_tokens = self.pool(x, cls_tokens)
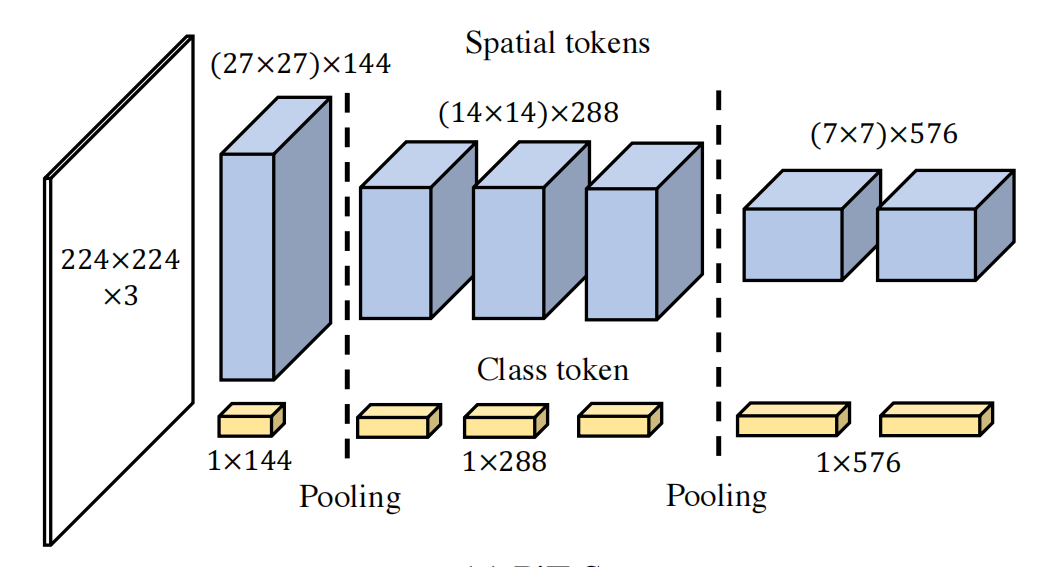
B, C, H, W = x.shape # x.flatten(2) transforms x into shape (B, C, H * W), where the height and width are combined into a single dimension. # .transpose(1, 2) swaps the channel and spatial dimensions to get shape (B, H * W, C) because transformers typically expect input where the second dimension represents the sequence length (here, the number of spatial tokens). x = x.flatten(2).transpose(1, 2) x = torch.cat((cls_tokens, x), dim=1)
x = self.norm(x) x = self.blocks(x)
cls_tokens = x[:, :token_length] x = x[:, token_length:] x = x.transpose(1, 2).reshape(B, C, H, W)
classClassAttn(nn.Module): # taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py # with slight modifications to do CA def__init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.): super().__init__() self.num_heads = num_heads head_dim = dim // num_heads self.scale = head_dim ** -0.5
defforward(self, x): B, N, C = x.shape # x[:, 0] 是 cls_token,在这部分中,q 是只由 cls_token 决定的 # q 的形状是 Batch x 1 x heads x head_length (C // heads) # C 是 embedding 的长度 # 虽然 3 维的 q 也能完整地存储 cls_token 的 q,但将 q 作为 4 维可以方便后面 q@k 的运算,因为 k 一定是 4 维,k 多一个维度是为了存储各种 patch 的 k # permute(0, 2, 1, 3) 后形状变成了 B x heads x 1 x head_length q = self.q(x[:, 0]).unsqueeze(1).reshape(B, 1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # k 是正常的 self attention 的 k,是 cls_token 和 patch 共同决定的 # k,v: B x heads x N x head_length k = self.k(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) q = q * self.scale v = self.v(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # attn: B x heads x 1 x N attn = (q @ k.transpose(-2, -1)) attn = attn.softmax(dim=-1) attn = self.attn_drop(attn)