Improving the adversarial transferability of vision transformers with virtual dense connection
Motivating Study
作者线性地减少 ViT 内各个组件的梯度的影响 (from 1 to 0 swith step size of 0.25)然后看看各个组件对迁移性的影响,得到的结论是消除 skip connection 后可迁移性下降最严重,无论是 Attention 模块还是 MLP 模块的 Connection

作者认为这是因为 skip connection 有助于传播来自 ViT 深层的梯度,而且 ViT 深层又捕获了更高级的特征,所以这些梯度更有助于可迁移性。
VDC
VDC(Virtual Dense Connection)是一种密集连接的方法。从 Motivating Study 的结论中可以看出,skip connection 对可迁移性至关重要。既然如此,我们就可以增加 skip connection 的使用程度,参考 CNN 中的 DenseNet 将每一层与其后的所有层全部连接。
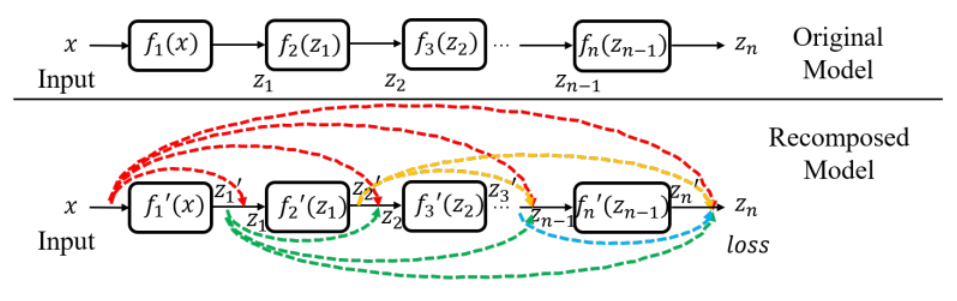
在具体实现上,由于不想改变模型的 forward pass,所以这种密集连接是虚拟存在的,也就是只在计算梯度的时候使用。假设·进行了密集连接,那模型中第
其中
从
令
然而,这样的计算方法是不高效的,为了解决这个问题,作者提出了 consecutive skip assumption。具体来说,就是在计算