Redis 集群
再谈Redis三种集群模式:主从模式、哨兵模式和Cluster模式 - 知乎
面试官:Redis有哪几种集群方案?原理和优缺点是什么? - 知乎
Redis Cluster集群原理+三主三从交叉复制实战+故障切换(十)-阿里云开发者社区
主从复制(Master-Slave)
读写分离
master 是系统中的数据中心,它不仅承担全部的写操作,还能处理读请求。当在master上执行任何改变数据的操作时,这些更改会自动且实时地同步到所有slave。
数据同步流是单向的,意味着数据只从master流向slave,确保了数据同步的一致性和可靠性。
复制原理
复制积压缓冲区(Replication Backlog):一个环形缓冲区,位于 主节点内存 中,用于存储最近一段时间的写操作命令。
主节点和从节点各自维护的一个 偏移量(Offset),表示已经同步的数据字节数。
- 主节点每次写入命令时,会记录这些命令在缓冲区中的偏移量。
- 从节点每次接收到数据后也记录自己的偏移量。
- 如果从节点的偏移量落后于主节点,则可以从积压缓冲区获取缺失的数据。
Redis 的主从复制机制均采用异步复制,也称为乐观复制,因此不能完全保证主从数据的一致性。
-
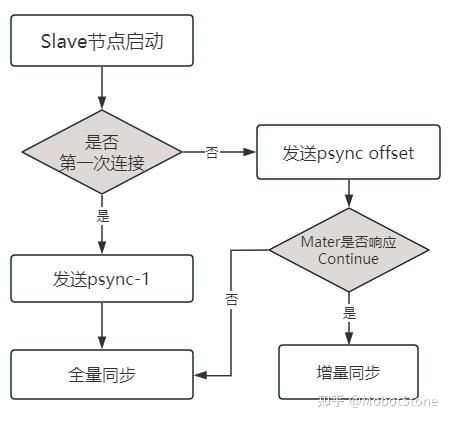
Slave 第一次连接:在 slave 第一次连接到主库时,将采用
psync复制方式进行全量复制。 -
正常运行期间:在正常运行状态下,从库通过读取主库的复制积压缓冲区来进行增量复制。
-
Slave 第二次连接(主库缓冲区未溢出):通过读取主库的缓冲区进行部分复制。
-
Slave 第二次连接(主库缓冲区溢出):采用
psync复制进行全量复制。Note
判断是否溢出:
从节点在断开之前会记录主节点的
master_replid(主节点的唯一标识符)。如果从节点重新连接的主节点 ID 与其记录的master_replid不匹配,说明主节点发生了重启或故障切换,缓冲区被清除,直接触发 全量复制(Full Resync)。如果从节点的偏移量不在缓冲区范围内,触发 全量复制(Full Resync)。
psync
哨兵(Sentinel)模式
它的核心优点在于能够自动实现主从切换和故障转移。
哨兵
一个哨兵可以监控多个master数据库,只需要提供多个该配置项即可。
1 | sentinel monitor <master-name> <ip> <redis-port> <quorum> |
哨兵启动后,会与要监控的master建立两条连接:
-
订阅master的
__sentinel__:hello频道-
新的主节点信息(IP:PORT)会通过
__sentinel__:hello广播给所有哨兵和从节点; -
哨兵会通过该频道互相感知
-
-
定期向 master 发送 INFO 等命令获取master本身的信息
哨兵操作:
-
定期向 master 和 slave 发送
INFO命令。这样可以获取到 maste 和其 slave 的信息; -
定期向 master 和 slave 的
__sentinel__:hello频道发送自己的信息。这样其他监听这些 master 和 slave 的哨兵就可以互相感知; -
定期向 master、slave、其他哨兵发送 ping 命令。如果被 PING 的节点超时未回复,哨兵认为其主观下线(sdown,Subjectively 主观地)。
如果下线的是master,哨兵会向其它哨兵发送命令询问它们是否也认为该master主观下线,如果认为下线的哨兵的票数达到一定数目,会认为该master已经客观下线(odown,Objectively 客观地),并选举领头的哨兵节点对主从系统发起故障恢复。
故障恢复
- 发现master下线的哨兵节点(我们称他为A)向每个哨兵发送命令,要求对方选自己为领头哨兵
- 如果目标哨兵节点没有选过其他人,则会同意选举A为领头哨兵
- 如果有超过一半的哨兵同意选举A为领头,则A当选
- 如果有多个哨兵节点同时参选领头,此时有可能存在一轮投票无竞选者胜出,此时每个参选的节点等待一个随机时间后再次发起参选请求,进行下一轮投票竞选,直至选举出领头哨兵
- 选出领头哨兵后,领头哨兵开始对系统进行故障恢复,从出现故障的 master 的从数据库中挑选一个来当选新的 master,选择规则如下:
- 所有在线的 slave 中选择优先级最高的,优先级可以通过 slave-priority 配置
- 如果有多个最高优先级的 slave,则选取复制偏移量最大(即复制越完整)的当选
- 如果以上条件都一样,选取 id 最小的slave
Cluster 模式
哨兵模式无法解决Redis容量受限于单机配置的问题。Cluster模式实现了Redis的分片存储,即每台节点存储不同的内容。
Cluster采用无中心结构,它的特点如下:
- 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽
- 节点的 fail 是通过集群中超过半数的节点检测失效时才生效
- 客户端与redis节点直连,不需要中间代理层.
- 客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
数据存储
Redis Cluster 使用哈希槽(hash slot)机制来分配数据。多节点平均分配 16384个 哈希槽。
数据将根据其 key 的 CRC16 算法结果取余 16384 得到其存储的节点。
在读取数据时,也是同样的算法判断其属于哪个节点。
新增节点
均匀地从原先的节点所管理的哈希槽的头部分配一些哈希槽给新的节点,也就是说新的节点管理的哈希槽不是连续的,但是其总数和其他节点是一样的。
比如 ABC 节点建立后
- 节点A负责管理0至5460号槽;
- 节点B负责管理5461至10922号槽;
- 节点C负责管理10923至16383号槽。
又添加一个节点 D
- 节点A:1365-5460
- 节点B:6827-10922
- 节点C:12288-16383
- 节点D:0-1364,5461-6826,10923-12287
删除节点:删除节点时,其管理的哈希槽会被迁移到其他节点上。迁移完成后,该节点即可被安全移除。
备用节点
Cluster模式集群节点最小配置6个节点(3主3从,奇数,因为需要半数以上),其中主节点提供读写操作,从节点作为备用节点,不提供请求,只作为故障转移使用。
一台机器上,可以部署主从节点,但是他们并不是对应关系,从节点是另外的机器上的主节点的备用节点,来避免一台机器崩溃后数据全部丢失。
通讯原理
redis集群采用gossip协议,gossip协议工作原理就是节点彼此不断交换信息,一段时间后所有的节点偶会指定集群完整信息,因此只需要在一台节点配置集群信息所有节点都能收到信息,只在一个节点上配置也可以同步到所有配置。
-
集群中的每一个节点都会单独开辟一个tcp通道用于节点之间彼此通信,通信端口在基础端口上增加10000
-
每个节点在固定周期内通过特定规则选择结构节点发送
PING消息,接收到PING消息的节点用PONG作为消息响应。在发送PING或PONG消息时,节点不仅会传递自己的状态信息,还会附带其已知的其他节点的状态信息。集群中每个节点通过一定规则挑选要通信的节点,每个节点可能知道全部节点的信息,也可能知道部分节点信息,只要这些节点彼此可以正常通信,最终他们就会达成一致的状态,当节点出现故障,新节点加入,主从角色变化等,彼此之间不断发生ping/pong消息,最终达成同步的模板
Note
Gossip 协议的工作原理
- **定期通信:**每个 Redis 节点都会定期向其他节点发送
PING消息,用于检测节点是否在线,并传递本节点已知的集群状态信息。如果一个节点收到PING消息,它会返回PONG作为确认。 - **节点状态传播:**在发送
PING或PONG消息时,节点不仅会传递自己的状态信息,还会附带其已知的其他节点的状态信息。 - **节点选择:**每个节点会随机选择其他节点作为通信对象,这种随机选择确保了状态信息能够在整个集群中快速传播。
- **状态更新:**当节点收到其他节点的状态信息后,会根据消息中的信息更新自己维护的节点状态表。这包括:
- 节点在线/离线状态(PFAIL、FAIL)
- 节点角色(master/slave)
- 节点 IP 和端口信息
- 节点所持有的槽位信息(slots)
消息类型:
- **PING:**主动发送的健康检查消息,附带本节点和已知其他节点的状态信息。
- **PONG:**对 PING 消息的确认响应,通常也携带其他节点的状态信息。
- **MEET:**用于引导新节点加入集群。一个节点向新节点发送 MEET 消息后,新节点获取到了集群其他阶段的消息,开始与集群中的其他节点通信。
- **FAIL:**当一个节点被认为不可用时(如多次 PING 超时无响应),其他节点会通过 Gossip 协议传播该节点的 FAIL 状态。