决策树:ID3、C4.5、CART 及其剪枝策略
决策树的一般构建方法
- 创建一个根节点
- 从现有的所有叶子节点中,选择其中一个样本类别不全部相同且属性列表不为空的节点
- 从选择的节点的属性列表中根据一定算法选择一个属性
- 根据选择的属性的取值划分该节点中的样本,分裂出新的叶子节点,并将叶子节点的属性列表设置为当前属性列表去掉划分的属性
终止条件:
| 终止条件 | 描述 |
|---|---|
| 纯度达到 | 当前节点样本属于同一类别 |
| 属性用尽 | 没有剩余可用属性,如果仍不纯则使用节点内多数的标签 |
| 样本过少 | 当前样本量小于设定阈值 |
| 信息增益小 | 划分后信息增益不足 |
| 深度限制 | 达到最大深度限制 |
ID3 算法
使用信息增益作为划分属性的选择标准:信息增益=整个数据集的标签分布的熵-某个属性划分子集后的期望熵
对于包含
按照 属性
以属性
如果
ID4.5 的特点:
- 每次只选择一个属性做划分;
- 倾向于选择取值多的属性,因为那样会把数据集分成多而纯的子集,每个子集的熵都很低;
- 单变量决策树,每次只考虑一个属性,不考虑属性之间的相互关系
C4.5
信息增益率取代信息增益
使用 信息增益比例(Gain Ratio)来进行划分选择:
其中,IV(分裂信息)定义为(假设
这样可以惩罚取值太多的属性,更公平地衡量不同属性的划分效果。其含义是按照
支持连续属性
对于连续属性
枚举所有可能划分点,对于每个候选点
处理缺失值
除了使用常用值、平均值之外,还可以按照概率分配:
- 为属性的每一个取值分配一个概率
- 在划分时,如果样本的划分属性缺失,则按照分配的概率选择分配到哪个节点
CART
Classification And Regression Tree
二叉树构建过程
分类任务,对于每个特征
-
如果是离散特征:尝试将取值根据划分点
split划分为两个集合。分别计算两组样本的标签的基尼指数,设一个节点中第个类别的分布是 ,共有 个类别,则其样本集分布 的基尼指数为: 特别的,对于二分类的样本,如果第一个类的在样本集中的分布是
,则: 基尼指数越小,表示样本类别分布越均匀,表示样本集
的不确定性更低。选择 split时,选择能够最小化切分后的加权 Gini 的split(表示节点总样本数, 分别表示二分后两组样本的数量): 对所有属性都选择
split并计算其划分后的加权基尼指数之后,选择最小的一个属性进行二叉分支。 -
如果是连续特征:枚举所有可能的划分值(见 C4.5连续属性),同样计算他们的加权Gini,选择最小的划分点。
回归任务:与分类任务一样,但是把 Gini 换成 MSE,对于每个节点,其预测为其所有样本的均值,故其 MSE 为:
递归地对所有的节点执行以上操作,直到达到终止条件。
终止条件
- 当前节点样本全属于同一类;
- 样本数量小于阈值;
- 树深达到
max_depth; - 基尼指数下降太小(低于某个增益阈值)
剪枝策略
代价复杂度剪枝
CART 使用 代价复杂度剪枝(Cost Complexity Pruning)
-
构造完整树;
-
自底向上考虑是否“剪掉”某个子树,从叶子节点开始逐步考虑是否合并它们的父节点,从而剪掉“枝叶”部分,达到简化树结构的目的。
-
在决定是否剪掉以
为根节点的子树 的时候,我们考虑剪前后的损失函数 和 ,其中 表示 合并了其子孙的所有样本,故叶子数量为 1, 是超参数,用于平衡损失和复杂度, 是以 为根的子树的叶子中的样本数量:
在选择
悲观剪枝
通过比较“保留子树”与“剪成多数类叶节点”两种方案的估计错误率,如果剪枝后效果更好或复杂度更低,就执行剪枝。
以
-
单节点分类错误率:
-
子树节点分类错误率是所有叶子节点的平均结果:
Note
根据中心极限定理,二项分布
连续修正(continuity correction)是指在将离散分布(如二项分布)近似为连续分布(如正态分布)时,为了提高近似精度,对计算的临界值做出±0.5的调整。
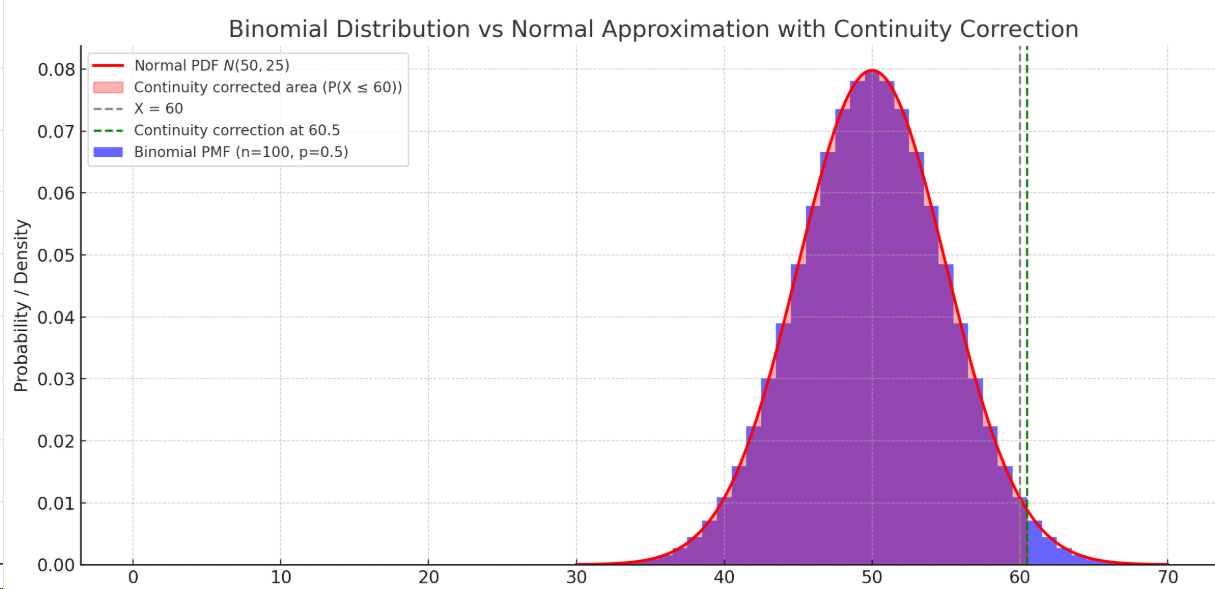
在上图中,我们试图用一个正态分布来近似一个二项分布。然而,在二项分布中,
将二项分布近似为正态分布后,我们可以得到以
其中
其中,左边是我们构造的原子树的误差数的上界,
剪枝过程:
- 先构建完整树;
- 自底向上遍历每个非叶子节点;
- 比较该子树的错误数上界 与 其下所有节点合并为叶节点后的估计错误数:
- 若满足上面的不等式就执行剪枝。
预剪枝
除了后剪枝外,也可以采用一些预剪枝策略,比如:
- 标准提升不足:若分裂节点后,判断是否分裂的标准的提升小于阈值(如基尼系数没有下降多少),则停止构建分支。
- 树的最大深度:限制树的层数。
- 节点样本数下限:若节点样本数小于设定阈值停止分裂,即便不纯。
- 类别纯度达标:若节点中某一类占比超过阈值则停止分裂,即便不纯。