统计学:假设检验
概论
假设检验是用于检验现有数据是否足以支持特定假设的方法。
- 原假设/零假设
:想要拒绝的假设,是一种默认立场或初始假设。它通常是一个我们想要通过数据去“推翻”的假设; - 备择假设
:与原假设对立的假设,通常是我们希望通过数据来支持的假设。
在进行假设检验时,可能会出现两种错误:
- 弃真错误(第一类错误,
错误):原假设是正确的但是被拒绝了; - 取伪错误(第二类错误,
错误):原假设是假的但是被接受了,也就是备择假设是正确的但是没有被接受;
注意,我们不能靠举例子来证明一个命题是正确的,但是你可以靠举出一个反例来证明一个命题是错误的,所以在面对原假设时,我们只能预设其是错的,看看能不能找出其是错的证据(判断样本数据是否提供了足够证据来拒绝原假设);不能证明出其是对的,我们只能说“我们不能拒绝原假设”。
拒绝域、临界值、显著性水平、p 值
显著性水平
如果希望拒绝原假设时的证据更加充分,则应该设置更小的显著性水平,此时原假设被拒绝的概率更小,如果这么小的概率仍被拒绝,则说明拒绝它的时候证据更充分,也就是犯第一类错误的概率越小。反之,如果想要不拒绝原假设的时候证据更加充分,则应该设置更大的显著性水平。越想拒绝原假设
显著性水平
对于单尾检验,拒绝域落在一侧,双尾检验则将拒绝域一分为二,并确保整个拒绝以相应概率反应这个检验水平,也就是两侧各占
p 值即某个小于等于拒绝域方向上的一个样本数值的概率,也就是用样本值在概率分布上确定一条线,然后这条线往拒绝域方向上的累积概率。利用样本进行计算,然后判定样本结果是否落在假设检验的拒绝域以内,也就是说,我们通过 p 值确定是否拒绝原假设。
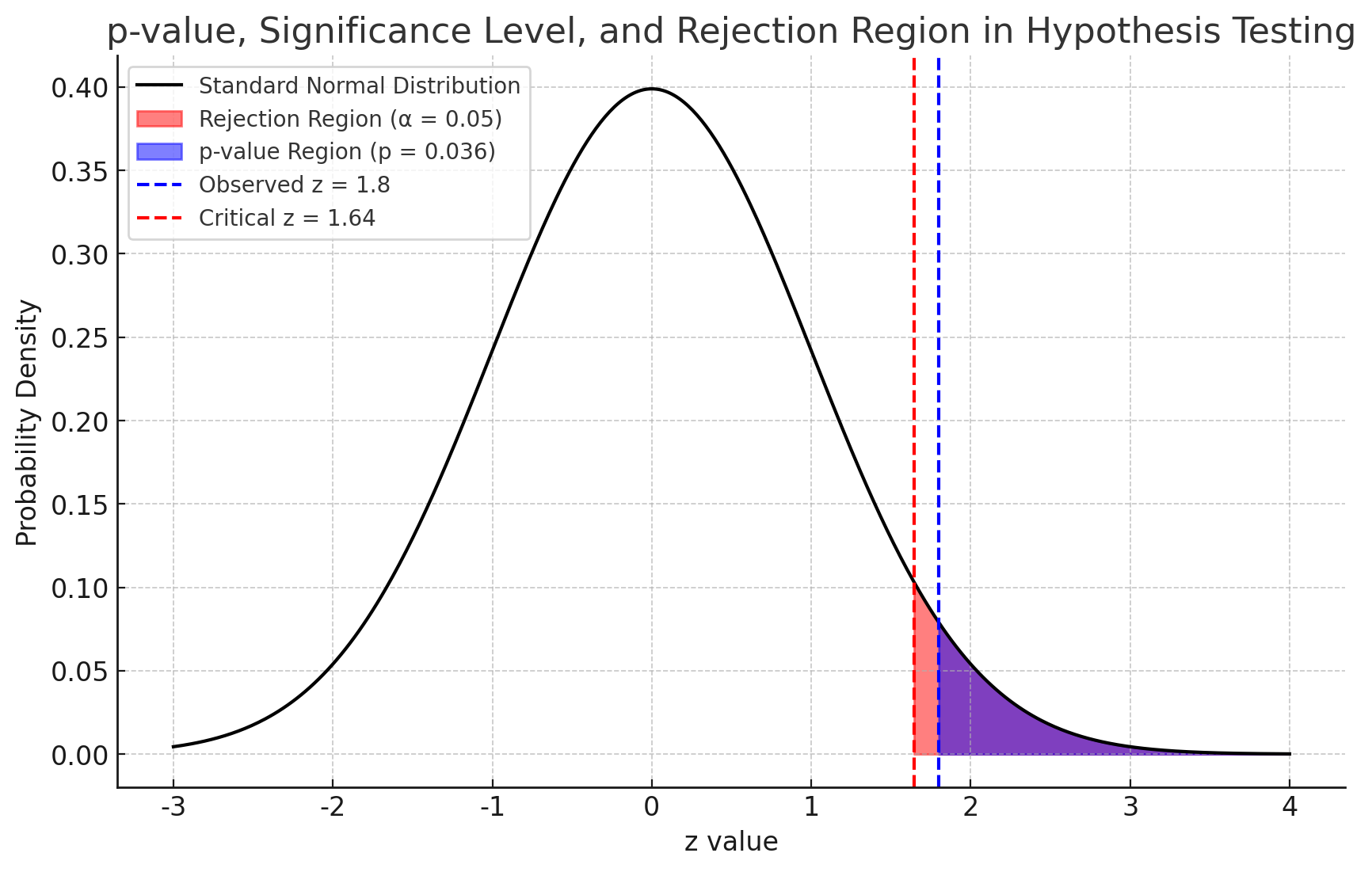
第一类错误的概率由
为接受
我们可以计算
所以,我们在计算出
检验功效,指的是在
z 检验
我们要检验样本均值是否服从一个假设的均值和方差。比如我们想检验整体的分布式是否是
将我们样本的结果根据这个均值和方差进行标准化,表示该样本是总体正态分布标准化后的一个取样的值,称为
由于
t 检验
t 分布
当你从正态总体中抽样,但不知道总体标准差,只能用样本标准差
不再服从标准正态分布,而是服从一个 t 分布,其自由度为
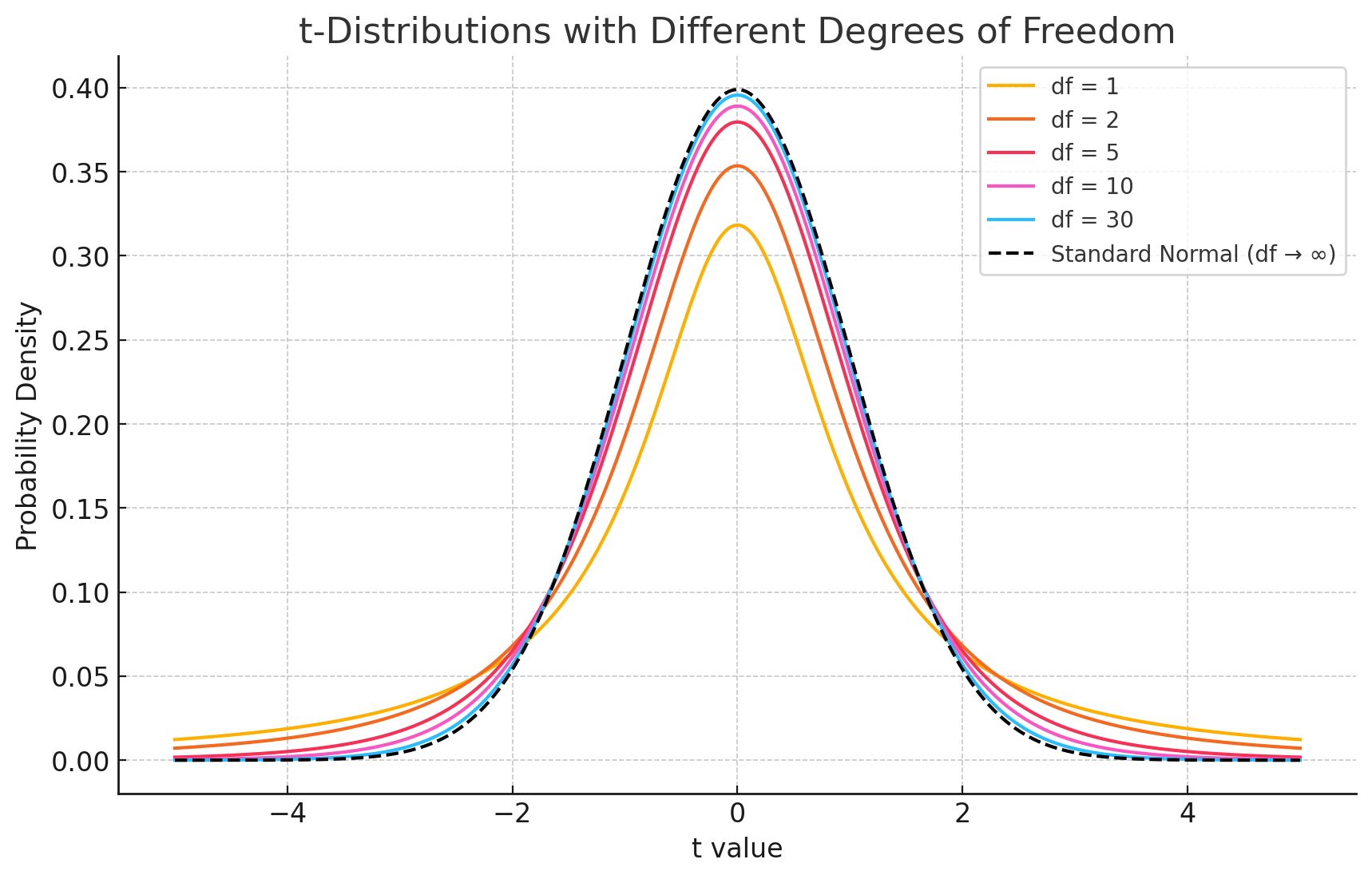
t 统计量
- 单样本均值检验(One-sample t-test):用于检验 总体方差未知、正态数据或近似正态的 单样本的均值 是否与 已知的总体均值相等
- 两独立样本均值检验(Independent two-sample t-test):用于检验 两对独立的 正态数据或近似正态的 样本的均值 是否相等,这里可根据总体方差是否相等分类讨论
- 配对样本均值检验(Dependent t-test for paired samples):用于检验 一对配对样本的均值的差 是否等于某一个值
原假设
- 单样本:
- 独立样本:
- 配对样本:差值均值 = 0
备择假设
- 双尾:
- 左尾:
- 右尾:
如果计算出的
假设我们检验样本均值
其中:
:样本均值 :原假设下的理论均值 :样本标准差 :样本大小 - 自由度:
然后查 t 分布的临界值(
卡方检验(Chi-square Test)
$\chi^2 $ 分布
卡方分布可以校验观测结果和期望结果之间的差别是否存在显著性:
- 检验拟合优度,也就是一组给定数据与指定分布的吻合程度;
- 检验变量独立性,也就是检验变量之间是否存在关联;
卡方分布可以通过一个参数
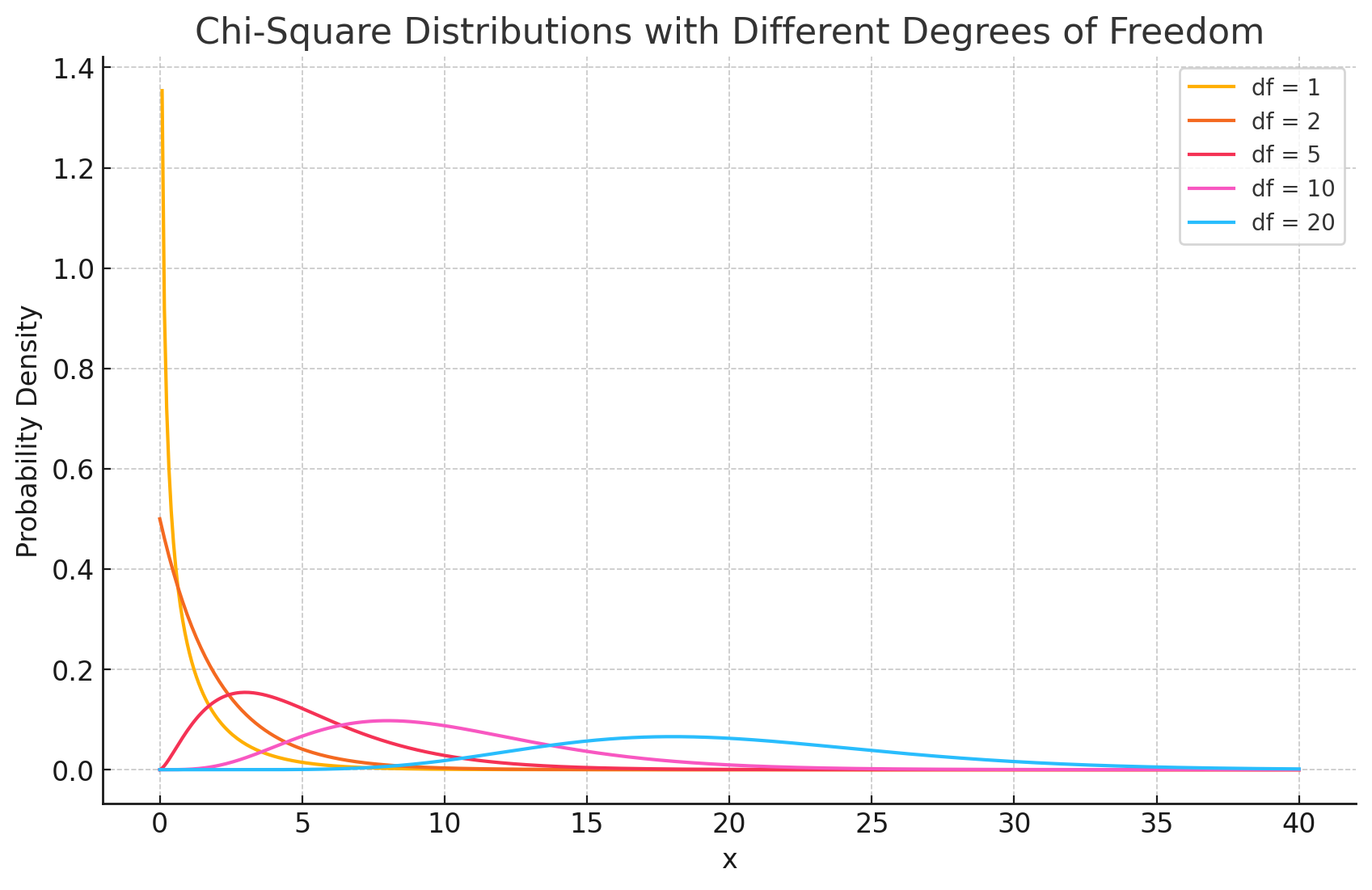
自由度 = 独立信息的数量 = 可自由变化的数据项数,比如总共有
其中每个
拟合优度检验
检验观测频率是否符合期望分布。用
然后再根据这个统计量以及卡方分布的概率表来计算 p 值,并和显著性水平比较判断是否拒绝
其中
独立性检验
判断两个分类变量是否独立。假设:
和拟合优度检验不同的是,我们此刻已经没有了期望频数。为了得到期望频数,我们用联合观察频数在某个事件上的边缘总和作为该事件的期望频数,并进一步计算出概率。由于假设两个变量独立,所以我们可以用概率相乘作为两个事件同时发生的概率:
有了期望频数后,对于所有联合事件,我们计算其期望分布,将结果和观测分布用于计算卡方值:
自由度为:
A/B 测试
A 页面 vs B 页面,哪个带来更高的点击率?
原价格 vs 新价格,哪个转化率更高?
老广告 vs 新广告,哪个平均收入更高?
原假设
备择假设
计算 t 统计量(自由度为
其中,
其中:
Note
每个样本方差
注意分母是
参考资料
- 深入浅出统计学(中文版)
- 假设检验——这一篇文章就够了
- Hypothesis Testing(假设检验) - 知乎
- ChatGPT