推荐系统: 召回
协同过滤
ItemCF
用用户行为来标记物品特征,用物品特征之间的相似度来给用户推荐相似的物品。
也可以将用户活跃度考虑其中,对异常活跃的用户进行惩罚 (
Swing CF
解决小圈子问题,即用用户行为给物品标记特征的时候,用户行为不一定是由用户感兴趣引起的,而可能只是这群用户在一个小圈子里互通信息,而 ItemCF 会误认为这体现了物品之间的相似性。
首先在行为相关性中引入连续时间衰减因子,然后引入基于交互数据的聚类方法解决数据稀疏的问题,旨在帮助用户找到互补商品。互补相关性主要从三个层面考虑,类别层面,商品层面和聚类层面。
- 类别层面 首先通过商品和类别的映射关系,我们可以得到 user-category 矩阵。随后使用简单的相关性度量可以计算出类别
跟 的相关性。
UserCF
根据用户相似性来推荐,用户 A 喜欢某个内容,用户 B 和用户 A 兴趣相似,则把这个内容也推给用户 A。对于用户
计算用户之间的余弦相似度:
对于过于热门的物品,就无法用于计算相似度,大家都喜欢的东西无法体现独特的兴趣。于是,把
考虑到用户评分的偏好不同,有的用户喜欢打高分,所以可以考虑到这个评分的偏置,也就是将用户对所有物品的平均分考虑进来
-
Triplet logistic loss,是 Triplet hinge Loss 的平滑版本,让梯度不消失:
是超参数,控制损失函数的形状 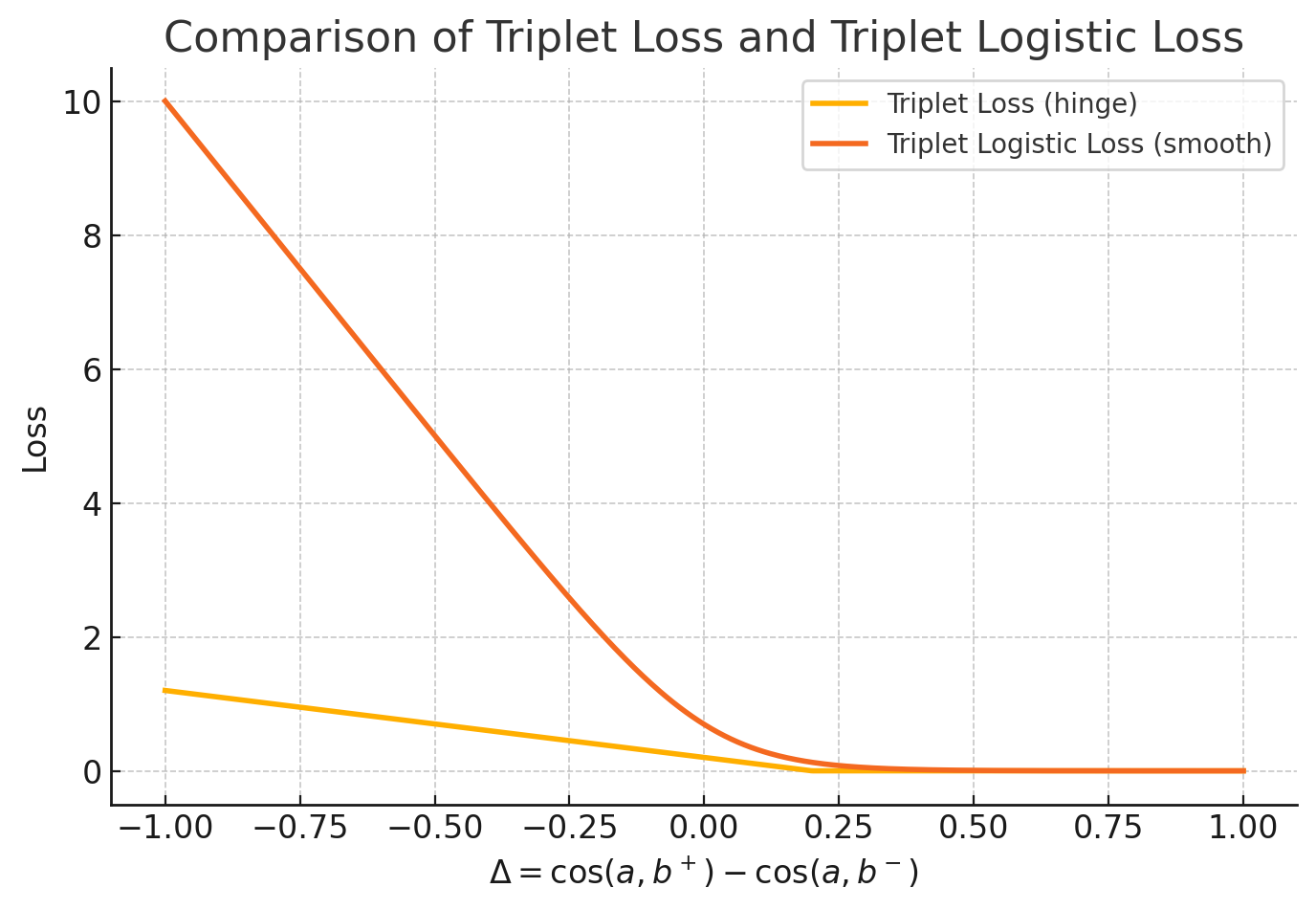
-
InfoNCE:
- 多个负样本参与
- softmax 归一化
是温度超参数
-
Listwise:用一个正样本和多个负样本组成同时训练,将所有余弦相似度经过 Softmax 转化为概率分布后与 One Hot 编码(正样本为1,其他为0)做交叉熵。
正负样本的选择
少部分的物品占据大部分的点击,导致正样本大多是热门物品,所以在采样正样本的时候可以过采样冷门物品,或者降采样热门物品。
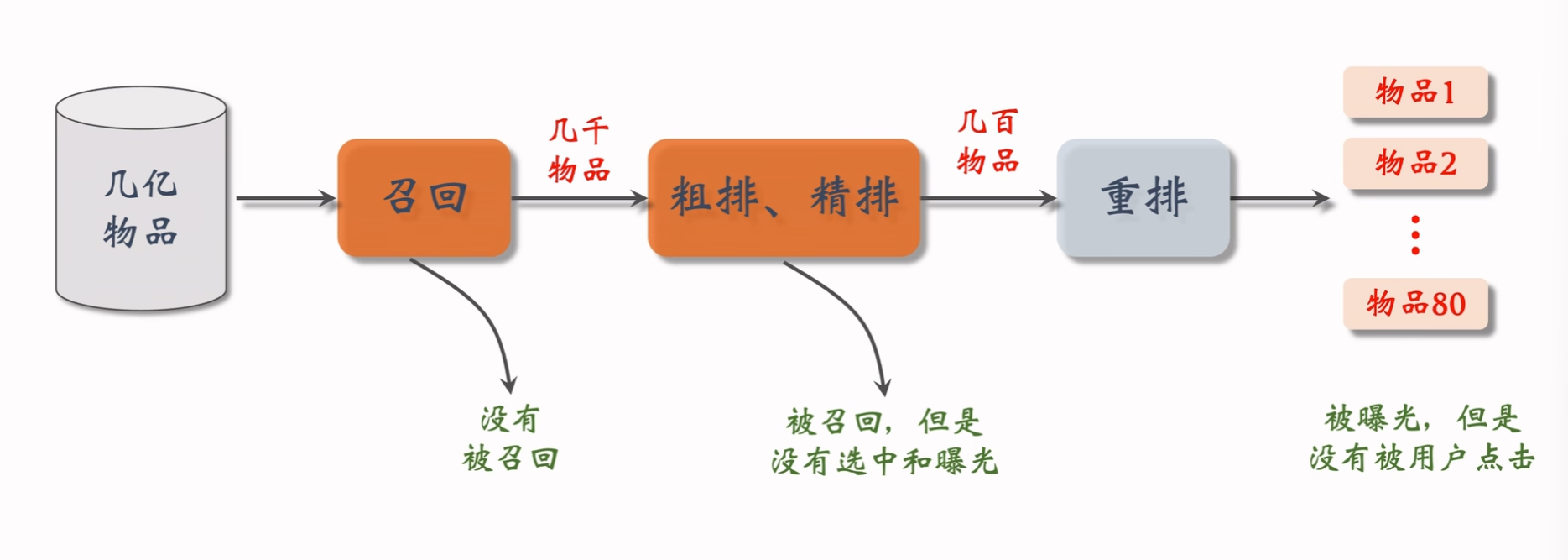
负样本采样:
-
简单负样本一:全体物品抽样负样本:大多数物品都没有被召回,所以其实未被召回的物品约等于全体物品,可以直接从全体物品中做抽样,作为负样本:
-
均匀抽样:冷门的物品是多数,均匀地抽样会导致负样本大多数是冷门物品,对冷门物品不公平;
-
非均匀抽样:打压热门物品,负样本抽样概率与热门程度正相关。比如每个物品被抽样的概率正比于其点击次数的0.75次方(经验值)
-
-
简单负样本二:Batch 内负样本:Batch 内有多个<用户,物品>对,存储用户对物品的点击,然后可以得到每个对都是正样本,而跨对的用户与物品匹配都是负样本(由于是随机抽样的,所以用户大概率不喜欢其他对内的物品)
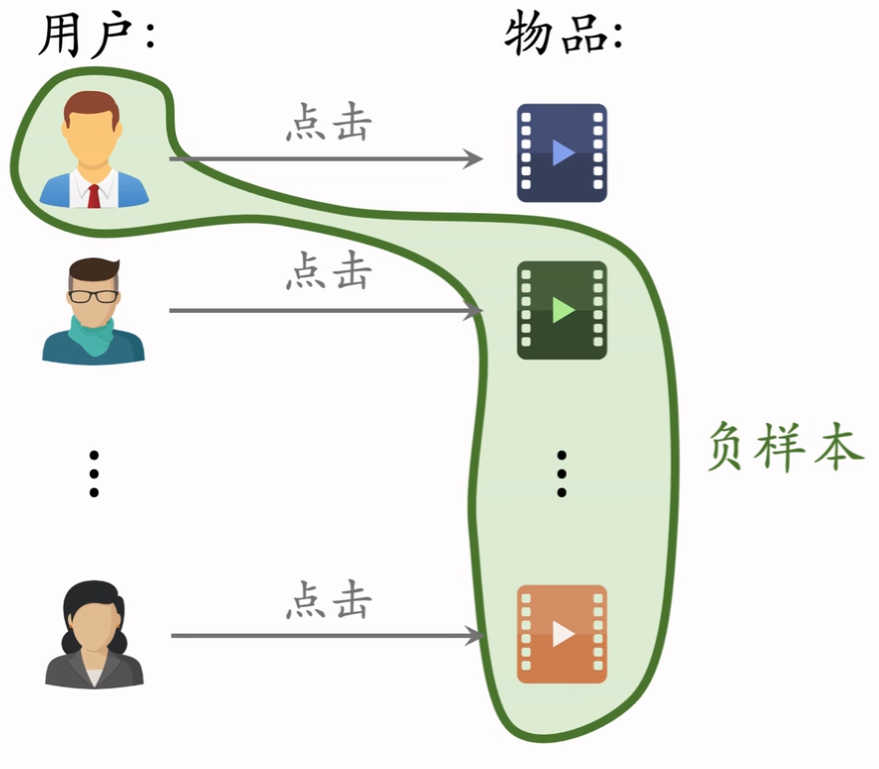
但是这样做的话,一个物品出现在这个 Batch 内的概率正比于点击次数,因为只有被点击才可以组成<用户,物品>对,所以其正比于物品被点击的次数。而经验值告诉我们应该正比于点击次数的0.75次方:所以此时应该根据物品被采样的概率减去一定的相似度,也就是
, 是物品 被采样的概率,这样可以避免过分打压热门物品。 -
困难负样本:被召回了,但是被粗排淘汰的物品(比较困难)、精排分数靠后的物品(非常困难)这两种样本说明用户可能对他们有一定的兴趣,但是他们仍然是负样本,这两者在分类中容易被归为正样本,准确率较低。
-
工业界常常混合简单负样本和困难负样本作为负样本数据,比如 50% 从全体抽样,50%从排序淘汰中抽样。
Caution
曝光但是没点击的不能作为负样本。
能通过粗排和精排最终曝光给用户说明你这个样本已经是用户比较感兴趣的了,这类样本不能作为训练召回模型的负样本。召回模型只是为了区分有兴趣与否,而不是兴趣的相对大小。用户没有点击,不代表不敢兴趣,而是对其他更感兴趣。
线上召回
先把物品 <embedding, id> 存储到向量数据库。而用户塔在线上实时计算,因为用户的特征不稳定,可能随时发生变化,会通过网络得到不同的结果。
线上实时计算得到用户向量 a,然后在向量数据库做实时查找得到最近领的 k 个物品 ID。
模型更新
- 全量更新:用昨天前天的数据训练模型 1 epoch,每条数据只用一次,发布新的用户塔神经网络和物品向量。
- 增量更新:Online Learning。流式处理实时收集线上数据,做流式处理。增量更新 ID Embedding 层的参数,锁住了全连接层。
增量更新是按照数据从早到晚的顺序,做 1 epoch 训练,而全量更新是 random shuffle 一天的数据,做 1 epoch 训练。随机打乱后,可以避免每个时间段内兴趣不同带来的偏差,学到更鲁棒的特征。
双塔模型的缺点
表达能力有限:双塔模型只通过简单的向量相似度(如内积、余弦相似度)建模 query 和 item 的关系,无法捕捉高阶交互特征。面对复杂行为模式、细粒度用户偏好时,表达能力不足。
无法建模跨塔交叉特征:Query 和 Item 在编码时是相互独立的,没有共享信息流。无法像单塔模型(例如深度交叉网络 DCN、DIN、DIEN 等)那样直接捕获 query-item 的联合特征和动态交互。
冷启动问题更明显:对新用户、新物品,双塔模型只能依赖侧信息(profile、metadata),但没有交叉特征帮助缓解冷启动。
低曝光物品表征难以学习:低曝光物品更少地得到交互,也就更好地拥有相关的用户交互信息。可用自监督训练物品塔。
自监督学习训练物品塔
把物品做不同的特征变换,得到不同的向量,然后输入物品塔神经网络,得到两个不同的 embedding。
- 对于同一个物品的不同特征表示
,应该让这两个拥有高相似度; - 对于不同物品的不同向量表征
,相似度应该尽量低,;
常见的特征变换方法:
-
随机选择一些离散特征,把它们全部遮住 Mask,比如类别直接变成 default 类别;
-
Dropout,对于可以有多个值的离散属性,随机丢弃其中 50% 的值,比如 <摄影, 自然> 变成 <自然>;
-
互补特征:将属性随机分成互补的两组,Mask 掉没在组内出现的属性;
-
Mask 关联的特征:计算特征两两之间的互信息:
总共有 k 个特征,随机选择一个特征作为种子,找到种子最相关的 k/2 个特征和种子一起保留,其余的 Mask 掉。
该方法效果更好,但是方法更加复杂,不容易维护,因为每次添加新的特征都要重新计算 MI。
模型训练:均匀从全体物品中抽样,得到 m 个物品。做两类特征变换,得到两组向量,分别包含 m 个。第
这
具体操作(batch 内负样本):
-
先对点击做抽样,得到
<用户, 物品>二元组 -
从全体物品中均匀抽样,得到 m 个物品,作为一个 batch
-
对原目标、自监督目标做多目标优化,使得损失减小:
Deep Retrieval (路径召回)
Deep Retrieval: Learning A Retrievable Structure for Large-Scale Recommendations
把物品表征为路径,线上查找用户最匹配的路径,路径可以用一个节点组成的向量表示,比如 path=[a,b,c]
,物品到路径的索引,一个物品可以有多条路径; ,记录每条路径上的物品,一条路径可以对应多个物品;
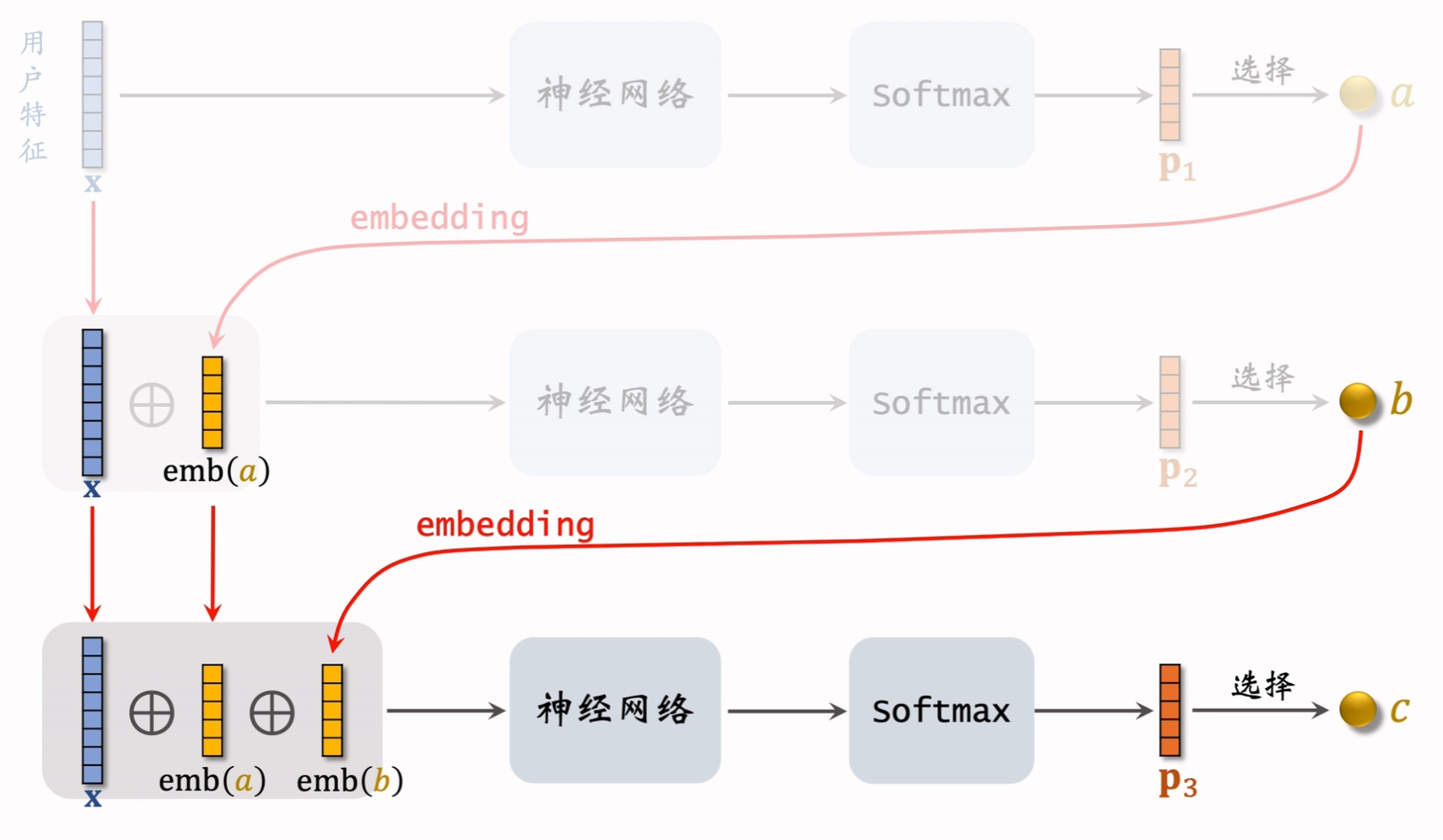
预估模型
预估用户对路径的兴趣,给定用户特征
得到上面三个条件概率后,就可以计算
所以就需要先得到
- 对于
,直接使用用户特征 作为输入,输入神经网络 ; - 对于
,将 与上一层模型得到的结果 的 embedding 进行 concat 后输入神经网络 ; - 对于
,将上面一层的输出 ,与上面一层的输入 concat 后输入神经网络 ;
对于每个神经网络,如果节点个数总共有
Beam Search
设置一个超参数 beamn size
在每次选择 beam size 大的节点作为该层的输出,总共会选出 beam size 的
记得对于每条路径,用户对他们的兴趣分数是不一样的,是
线上召回
- 从用户得到路径:给定用户特征,用 beam search 召回一批路径;
- 从路径得到物品:利用所有
path -> List<item>召回一批物品; - 对物品打分:对物品做打分和排序,选出一个子集,也就是并不是所有召回路径的物品都最终会被召回;
Warning
为了防止混淆,这里再次强调,路径只是物品的表征,并不是说路径上每一个节点都是一个物品。
训练
同时学习:
- 用户对路径的兴趣分数,也就是前面的
- 物品的路径表征
也就是我们要交替进行:
- 更新神经网络
- 更新物品表征
更新神经网络:用正样本进行训练(用户点击过的物品)。用户点击过某个物品,即表示该物品的
因为里面的用户对路径的兴趣分数
更新物品表征:计算 item 和 path 的相关性,即所有对物品感兴趣的用户,对该路径的兴趣分数(由神经网络预测得到)的累加:
有了
在选择时,为了避免过多的 item 集中在一条 path 上,还应该施加一个正则项,惩罚一条路径上存在过多的物品,对于路径
对于选出的路径集合
更新
其他召回通道
地理位置召回:GeoHash
作者召回:
-
有交互的作者召回:维护
用户->有交互的作者索引 -
相似作者召回:维护
作者->相似作者索引:
缓存召回:
- 复用之前的精排结果,因为可能大部分精排结果在重排后没有被曝光。
- 缓存退场:缓存大小固定,笔记成功曝光就退场、First in first out、重复召回超过 n 次就退场、达到时间阈值就退场。
曝光过滤
如果用户看过某个物品,则不再推荐。
在召回后才过滤,一般用布隆过滤器,Bloom Filter。
Bloom Filter:一种绝对否定、概率肯定的数据结构。把物品集合编码为
用
- 当物品哈希后某一位为 1,则表明可能曝光过,但也可能是哈希冲突的其他物品;
- 但如果是 0,则一定没曝光过。
如果
Bloom Filter 把一个未曝光物品设置为已曝光的概率是(
这样一来,可以看到误判的概率随着物品总数、向量维度的上升而上升,随着向量长度的上升而减小。
在设定可容忍的
Bloom Filter 缺点:不支持删除物品,无法消除物品对向量的影响;