Bert 初探
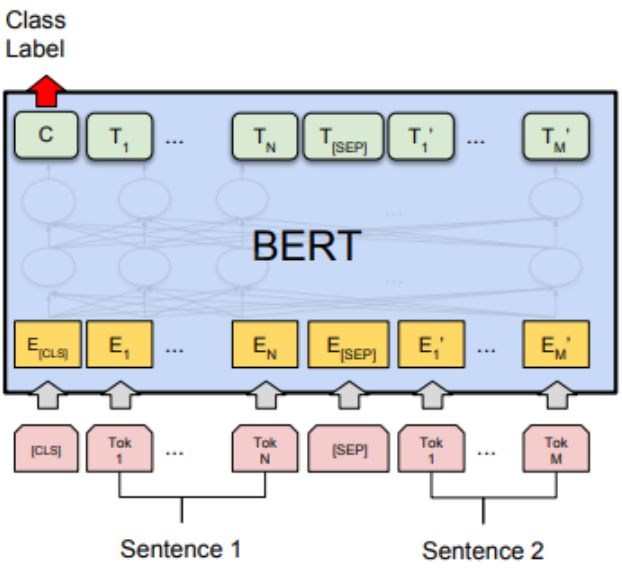
Embedding & 模型结构
由3️⃣种 Embedding 求和得到:
-
Token Embeddings (由
input_ids输入得到)词向量,BERT 在输入文本的最前面强制一个特殊 token:[CLS]标志,在 NSP 预训练中被训练为捕捉整个句子或句子对的全局语义; -
Segment Embeddings(由
token_type_ids得到) 表示词属于哪一段句子。比如问答任务中,我们输入:1
[CLS] Question [SEP] Answer [SEP]
其中,
Question中的每个词都会加上标号0,Answer中的每个词都会加上标号1,来帮助模型区分词属于哪个句子。 -
Position Embeddings 学习出来的位置编码;
在求出来后,还要进行 attention mask 0/1 掩码,屏蔽掉其中的 padding。
BERT 模型由多个 Transformer 的 Enoder 块(MHA、Add&LayerNorm、FFN、Add&LayerNorm)堆叠形成。
预训练
Masked LM
BERT 使用了 Transformer 的 Encoder 堆叠结构,而核心的 Self-Attention 在每一层都允许每个 token 看到序列中其他所有 token(除了被 mask 的位置),从而实现 上下文的双向融合。
在训练过程中作者随机mask 15%的token,最终的损失函数只计算被mask掉那个token。如果全部换成某个标记,比如 [MASK],会影响模型的性能,因为现实中遇不到这个 [MASK],所以10%的单词会被替代成其他单词,10%的单词不替换,剩下80%才被替换为 [MASK]。
Next Sentence Prediction
输入句子 A 和 B,让模型判断 B 是否是 A 的下一句。BERT 就使用 [CLS] 的表示
语料选取的时候选用document-level 的而不是sentence-level 的,这样可以训练处理连续长序列的能力。
微调
利用带有标注的小规模数据,通过反向传播更新所有参数,使得模型适应特定的任务。
BERT 输出一个序列向量:[CLS] 位的向量
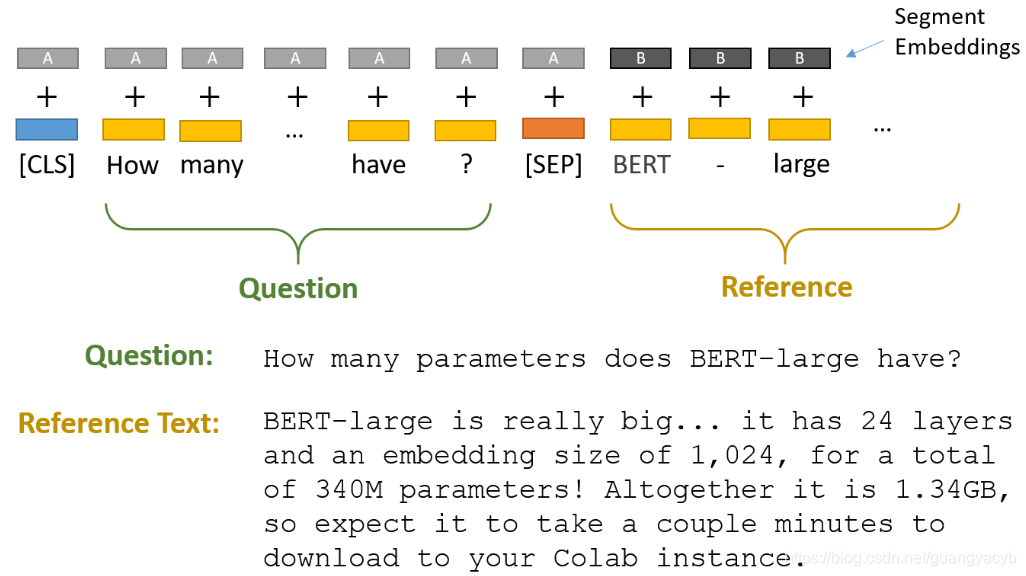
BERT 问答
在典型的 QA 任务(如 SQuAD)中,给定:
- 问题(question):如 “Where was Einstein born?”
- 上下文段落(context):如 “Einstein was born in Ulm, Germany in 1879…”
目标是从段落中找出一段文本作为答案子串,例如:“Ulm, Germany”。
将问题和参考文献用 [SEP] 链接起来加上 Segment Embedding。注意 [SEP] 的 Segment Embedding 保持和前面的句子一致。
1 | [CLS] Question Tokens [SEP] Context Tokens [SEP] |
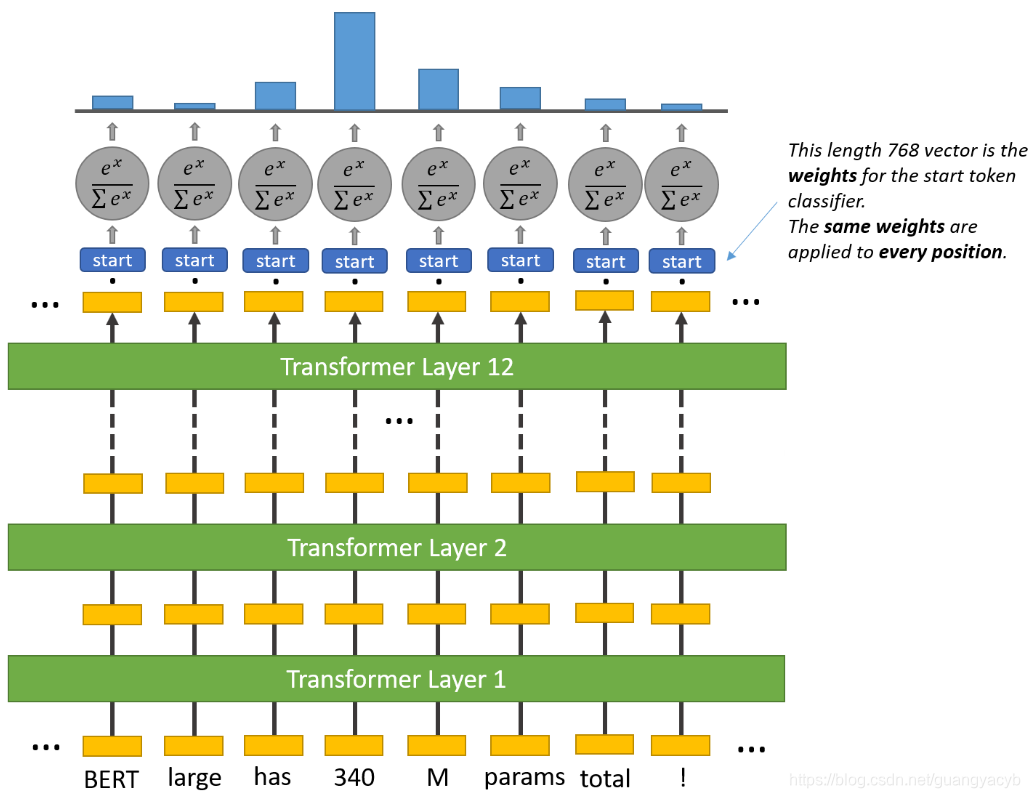
BERT 需要学习到参考文献中的哪个部分是问题的答案。也就是标记参考文献中答案的开始位置和结束位置。BERT 的输出是每个 token 的表示向量:
再添加两个线性层,用于预测起始位置得分,表示这个词作为起始位置的可能性:
结束位置得分,表示这个词作为终止位置的可能性:
再通过 softmax 得到所有词作为起始位置和终止位置的概率分布:
训练时,已知答案在 context 中的起始和结束位置使用交叉熵损失:
预测时,从所有可能的 j > i,找到 j 作为终止位置的得分加上 i 作为起始位置的得分的和,作为这个序列的
提取出来再映射回原始文本。
Note
如何找出最大的
设允许的答案最大长度是 start 分数。遍历 start 分数,在每步记录下最高得分及对应
时间复杂度为
序列过长问题
在于BERT中的 Position Embedding 和 Transformer 中的Positional Embedding实现方式并不一样,后者是通过公式计算得到,而前者则是学习得到的,最大长度会受到学习时的输入长度的限制。
除了对预训练模型重新训练外:
在训练阶段,以滑动窗口的形式进行采样构造得到多个子样本;然后将这些子样本作为训练集来训练模型;在推理阶段同样采取这样的方式对原始样本进行处理,并选择各个子样本中概率值最大的标签作为原始样本的标签。