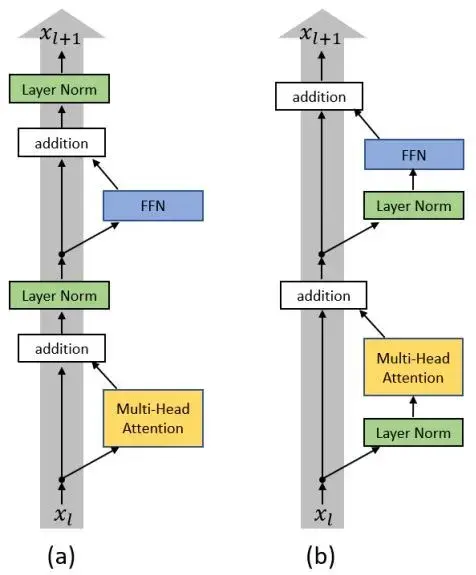
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
| import math
import torch
from torch import nn
def position_encoding(seq_len, d_model):
position = torch.arange(seq_len, dtype=torch.float).unsqueeze(1)
i = torch.arange(0, d_model, 2).float()
div_term = torch.exp(i * (-math.log(10000)) / d_model)
pe = torch.zeros((seq_len, d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
return pe
class MultiHeadAttention(nn.Module):
def __init__(self, head_num, d_model, dropout=None):
super().__init__()
self.q_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.output_linear = nn.Linear(d_model, d_model)
self.head_num = head_num
assert d_model % head_num == 0
self.d_model = d_model
self.d_k = self.d_model // head_num
self.dropout = Dropout(dropout) if dropout is not None else None
def attention(self, q, k, v, mask=None):
"""
Scaled Dot Product Attention
:param q: (Batch, H, LenQ, d_k)
:param k: (Batch, H, LenK, d_k),对于 Encoder 和 Decoder,LenQ = LenK
对于 Cross Attention,LenQ 是解码器序列长度,LenK 是编码器序列长度
:param v: (Batch, H, LenK, d_k) 和 k 相同
:param mask: 为 0 的地方会让 scores 的相同位置变成 1e-9.
考虑 padding 和 decoder 的 mask-attention 两种情况
1. future: (Batch, 1, LenQ, LenK) 对注意力分数进行下三角的遮蔽
2. padding: (Batch, 1, 1, LenK) 对padding部分遮蔽,即 [i, 1, 1, j] 表示第 i 条序列的第 j 个 token 是否 mask
score: (Batch, H, LenQ, LenK)
会被自动广播成 score 的形状
:return:
"""
d_k = q.size(-1)
scores = (q @ k.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = nn.functional.softmax(scores, dim=-1)
if self.dropout is not None:
p_attn = self.dropout(p_attn)
return p_attn @ v, p_attn
def forward(self, q, k, v, mask=None):
"""
:param q:
:param k:
:param v:
:param mask: (Batch, LenQ, LenK)
:return:
"""
if mask is not None:
mask = mask.unsqueeze(1)
batch = q.shape[0]
q = self.q_linear(q).view(batch, -1, self.head_num, self.d_k).transpose(1, 2)
k = self.k_linear(k).view(batch, -1, self.head_num, self.d_k).transpose(1, 2)
v = self.v_linear(v).view(batch, -1, self.head_num, self.d_k).transpose(1, 2)
attn_output, self.attn = self.attention(q, k, v, mask)
attn_output = attn_output.transpose(1, 2).view(batch, -1, self.d_model)
return self.output_linear(attn_output)
class LayerNorm(nn.Module):
def __init__(self, d_model, eps=1e-5):
super().__init__()
self.eps = eps
self.gamma = nn.Parameter(torch.ones(d_model))
self.beta = nn.Parameter(torch.zeros(d_model))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
x_norm = (x - mean) / torch.sqrt(var + self.eps)
return self.gamma * x_norm + self.beta
class PositionWiseFFN(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super().__init__()
self.w1 = nn.Linear(d_model, d_ff)
self.w2 = nn.Linear(d_ff, d_model)
self.dropout = Dropout(dropout)
def forward(self, x):
return self.w2(self.dropout(nn.functional.relu(self.w1(x))))
class Dropout(nn.Module):
def __init__(self, p):
super().__init__()
assert 0 <= p < 1
self.p = p
self.keep_prob = 1 - p
def forward(self, x):
if self.training:
mask = (torch.rand_like(x) < self.keep_prob).float()
return mask * x / self.keep_prob
else:
return x
class EncoderBlock(nn.Module):
def __init__(self, d_model, heads, dropout=0.1):
super().__init__()
self.norm1 = LayerNorm(d_model)
self.norm2 = LayerNorm(d_model)
self.mha = MultiHeadAttention(heads, d_model, dropout)
self.ffn = PositionWiseFFN(d_model, d_model * 4)
self.dropout = Dropout(dropout)
def forward(self, x, mask):
x1 = self.norm1(x)
x1 = self.mha(x1, x1, x1, mask)
x = x + self.dropout(x1)
x1 = self.ffn(self.norm2(x))
x = x + self.dropout(x1)
return x
class Encoder(nn.Module):
def __init__(self, vocab_size, d_model, N, heads, dropout):
super().__init__()
self.N = N
self.embed = nn.Embedding(vocab_size, d_model)
self.pe = position_encoding
self.layers = nn.ModuleList([EncoderBlock(d_model, heads, dropout) for _ in range(N)])
self.norm = LayerNorm(d_model)
self.d_model = d_model
def forward(self, src, mask):
x = self.embed(src)
x = x * math.sqrt(self.d_model) + self.pe(x.shape[1], self.d_model)
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
class DecoderBlock(nn.Module):
def __init__(self, d_model, heads, dropout=0.1):
super().__init__()
self.norm1 = LayerNorm(d_model)
self.dropout1 = Dropout(dropout)
self.norm2 = LayerNorm(d_model)
self.dropout2 = Dropout(dropout)
self.masked_attention = MultiHeadAttention(heads, d_model, dropout)
self.norm3 = LayerNorm(d_model)
self.dropout3 = Dropout(dropout)
self.cross_attention = MultiHeadAttention(heads, d_model, dropout)
self.ffn = PositionWiseFFN(d_model, d_model * 4)
def forward(self, x, encoder_output, src_mask, target_mask):
"""
:param x:
:param encoder_output:
:param src_mask: 把 encoder_output 中的 padding 部分的 attention 分数设成很小的值
防止 CrossAttention 去 Attend 无意义的值
:param target_mask: 同时负责 Mask 下三角的未来信息以及 target 的 padding 部分
:return:
"""
x1 = self.norm1(x)
x = x + self.dropout1(self.masked_attention(x1, x1, x1, target_mask))
x1 = self.norm2(x)
x = x + self.dropout2(self.cross_attention(x1, encoder_output, encoder_output, src_mask))
x1 = self.norm3(x)
x = x + self.dropout3(self.ffn(x1))
return x
class Decoder(nn.Module):
def __init__(self, vocab_size, d_model, N, heads, dropout):
super().__init__()
self.N = N
self.embed = nn.Embedding(vocab_size, d_model)
self.pe = position_encoding
self.layers = nn.ModuleList([DecoderBlock(d_model, heads, dropout) for _ in range(N)])
self.norm = LayerNorm(d_model)
self.d_model = d_model
def forward(self, target, encoder_output, src_mask, target_mask):
x = self.embed(target)
x = x * math.sqrt(self.d_model) + self.pe(x.shape[1], self.d_model)
for layer in self.layers:
x = layer(x, encoder_output, src_mask, target_mask)
return self.norm(x)
class Transformer(nn.Module):
def __init__(self, vocab_size, d_model, N, heads, dropout, *args, **kwargs):
super().__init__(*args, **kwargs)
self.encoder = Encoder(vocab_size, d_model, N, heads, dropout)
self.decoder = Decoder(vocab_size, d_model, N, heads, dropout)
self.linear = nn.Linear(d_model, vocab_size)
def forward(self, src, target, src_mask, target_mask):
e = self.encoder(src, src_mask)
d = self.decoder(target, e, src_mask, target_mask)
output = self.linear(d)
return output
|