推荐系统: 排序
多目标模型
结构
排序的依据:预估点击率、点赞率等多种分数,加权融合这些分数。
输入:
- 用户特征:用户 ID 和用户画像;
- 物品特征:物品 ID 和物品画像、作者信息;
- 统计特征:用户统计特征,比如点击了多少个物品;物品统计特征,比如获得了多少次曝光、点击、点赞;
- 场景特征:用户所处的地点、时间等;
以上特征 Concat 后,输入神经网络,再用多个 FFN (Sigmoid 函数映射到
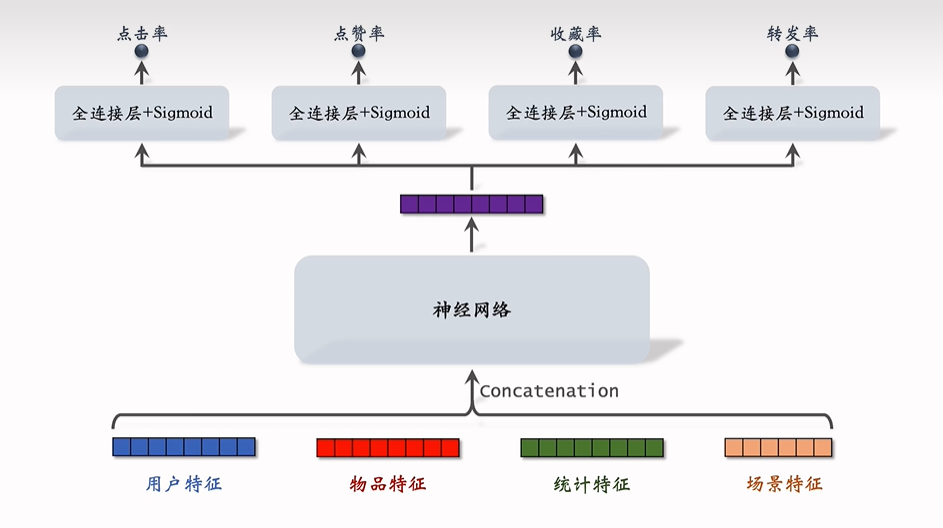
对于一个物品数据,我们已经知道了用户是否会对其做点击、点赞等,即
训练
设正样本和负样本的数量分别为
解决方法:负样本降采样;
负样本降采样后,需要进行预估值校准。对于整体而言:
- 真实的点击率:
; - 预估的点击率:
, 是采样率。
因此,如果我们得到了
Multi-gate Mixture-of-Experts (MMoE)
模型结构
在多目标网络的基础上,引入多个专家。对于每个目标,都使用所有专家输出的结果的加权平均作为预测。对于每个目标,其权重由一个单独的神经网络完成。
下图中:
和 分别表示针对某个目标的权重,注意经过了 Softmax 后,权重是概率的形式,所以此时 是期望(加权平均); - 第
号神经网络表示第 个专家(通常试一下 4 / 8 个); - 权重的数量等于专家的数量;
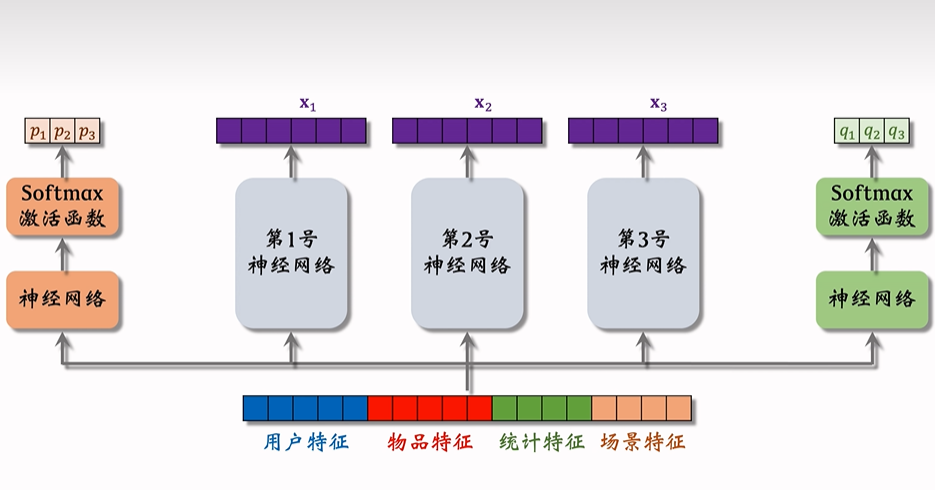
得到权重和专家的输出后,可以得到 MMoE 的预测结果:
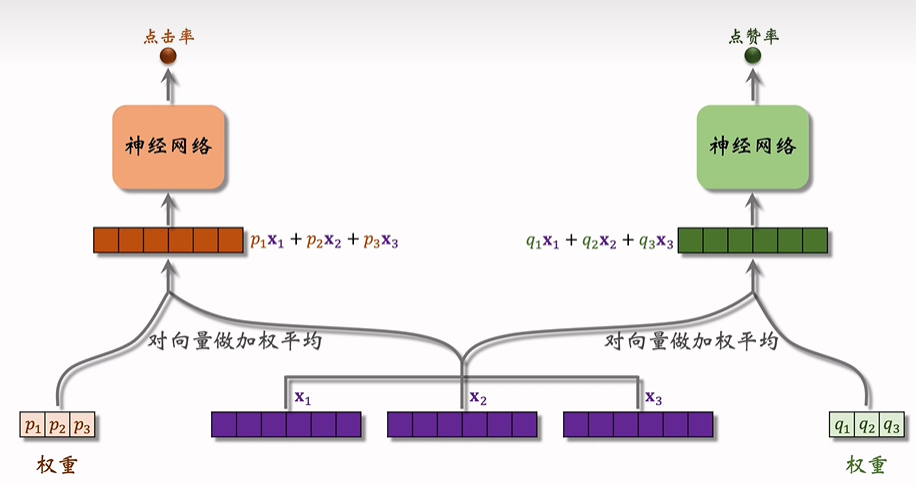
极化(Polarize)问题
当权重在 Softmax 之前,如果某个维度上非常大,Softmax 后这个维度会接近于 1,其余接近于 0,导致最终的预测只参考了一个专家的输出,没有发挥 MMoE 的优势。
专家极化
- 现象:一部分专家被大多数或所有任务频繁选择,变得非常活跃和重要;而另一部分专家则很少被选中,其参数得不到充分训练,逐渐“退化”。
- 结果:最终,有效的专家数量远少于你实际设置的专家数量。例如,你设置了8个专家,但可能只有3-4个是真正活跃的,其余4-5个几乎不起作用。这造成了计算资源的浪费。
任务极化
- 现象:某些任务会“霸占”某几个特定的专家,导致这些专家只为该任务服务,而与其他任务完全或几乎脱钩。
- 结果:这在一定程度上是MMoE期望达到的效果(捕捉任务特异性),但如果极化过度,会导致:
- 负迁移风险:如果两个任务本来有共享信息,但被完全分配给了不同的专家组,它们之间就无法进行有效的知识迁移。
- 模型脆弱:如果某个被“霸占”的专家训练得不好,那么依赖它的那个任务的性能就会受到严重影响。
解决方法:
- Dropout。对于 Softmax 的输出
个维度,每个维度都有 的概率被 Mask,强迫模型不仅仅参考某个专家的决策。 - Softmax 加温度
预估分数融合
加权和:将所有预测的分数以一定权重相加
点击率乘以其他加权和:也就是计算曝光后,点击和某种交互同时发生的概率。比如用户点击概率(点击/曝光)乘以点赞的概率(点赞/点击),才表示曝光后用户点赞的的概率,也是业务中实际的场景,比如用户只有点击进去后才有点赞按钮:
简单幂乘积:直接计算所有事件发生的联合分布,指数提供非线性调节能力:
在电商场景中,还会直接考虑其价格:
加权幂乘积:适合需要“短板效应”的场景。一个因素极低时,会显著拉低总分,指数提供非线性调节能力。相比简单幂乘积,其对零值鲁棒,不会因为某个维度的分数为 0 而直接淘汰该物品,并且加入了对某个维度的分数的直接缩放。
排名加权和:对于
特征
特征来源
用户画像(User Profile):用户 ID、人口统计学属性、账号信息(注册时间、活跃度等)、感兴趣的类目/关键词;
物品画像(Item Profile):物品 ID、发布时间、GeoHash、所在城市、物品描述等;
用户统计特征:
- 最近一段时间的曝光、点击、点赞等的数量;
- 对不同类目的物品做分桶,比如分别统计不同类目的点击率;
- 按照内容形式做分桶,比如图文、视频;
物品统计特征:
- 最近一段时间的曝光、点击、点赞等的数量;
- 按照其受众的人口统计特征做分桶,可以获得其受众的特征,比如性别、年龄;
- 作者的特征;
Note
相比较为静态的用户画像、静态的物品画像,其变化幅度非常小,所以主要考虑读取的速度要快。而对于统计特征,其每时每刻都可能在变化,所以也要求写速度要快,且不能直接用缓存数据。
场景特征:
- GeoHash、城市;
- 当前时刻;
- 是否是周末/节假日;
- 设备信息,不同设备品牌的用户可能有明显的区别;
特征处理
离散特征:embedding
连续特征:
- 分桶、变成离散特征;
- 做
,防止值域过大; - 转化为百分率做平滑;
特征覆盖率
一些特征会有缺失,很多特征不能覆盖 100%
提高特征覆盖率,可以让排序模型更加准确。
粗排模型
相比精排模型,粗排模型的输入集合可能很大,因此对推理的代价非常敏感,愿意以此牺牲一些准确性。
三塔模型。在用户塔、物品塔之外,引入了交叉塔。交叉塔
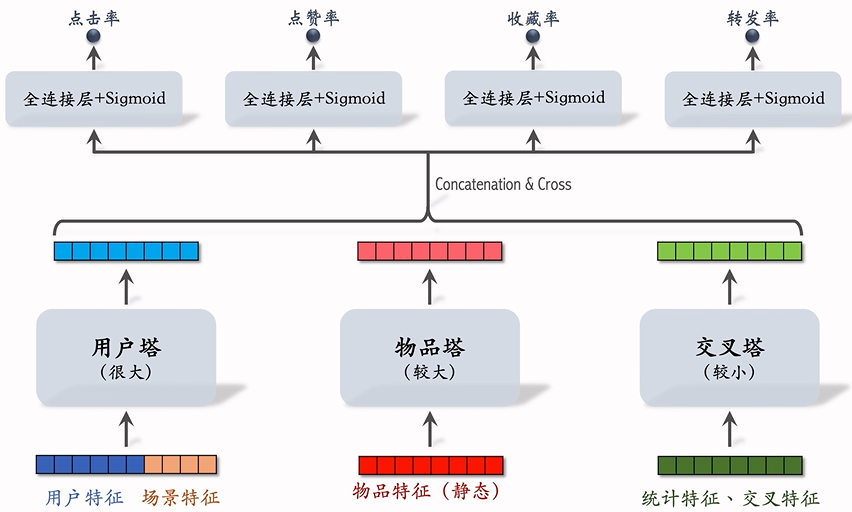
用户塔:每次推荐只需要一次推理,即便很大也容易负载;
物品塔:虽然每次推荐需要做多次推理,但由于物品特征相对静态,可以使用缓存,因此物品塔也可以做的比较大;
交叉塔:交叉塔的输入是统计特征、交叉特征。统计特征动态变化,因此需要多次推理,所以需要其比较小,通常只有一层、宽度小。
上层网络:输入无法缓存,所以每次都需要推理,无法缓存,是粗排模型的主要计算量所在。