大模型中的 MoE、V-MoE 以及 Deepseek-MoE
LLM MoE
在 Scaling Law 的背景下,越大的模型参数,往往意味着更强的性能。然而,过多的模型参数,会带来更大的计算开销。在此背景下,如何增大模型参数同时不增加计算开销成为 LLM 进步的问题。
在 Transformer 的 FFNN 中,我们常常使用 Dense 模型,每处理一个 Token,所有的参数都要参与计算。这就像去医院看个感冒,全院的医生(内科、外科、牙科…)都跑过来给你会诊,既浪费资源又慢。
MoE 模型引入了 稀疏性 (Sparsity) 的概念。它的 Transformer Block 中的 FFNN 被改造成了多专家网络,包括两个组件:
- Router (路由器/门控网络): 这是 MoE 的“分诊台”。它是一个轻量级的神经网络,负责看一眼输入的 Token,然后决定把它派给哪几个专家处理。
- Experts (专家): 原本的 FFN (Feed-Forward Network) 层被替换成了多个平行的 FFN,每一个就是一个“专家”。在输出时,只选择其中一个子集的专家的加权和。
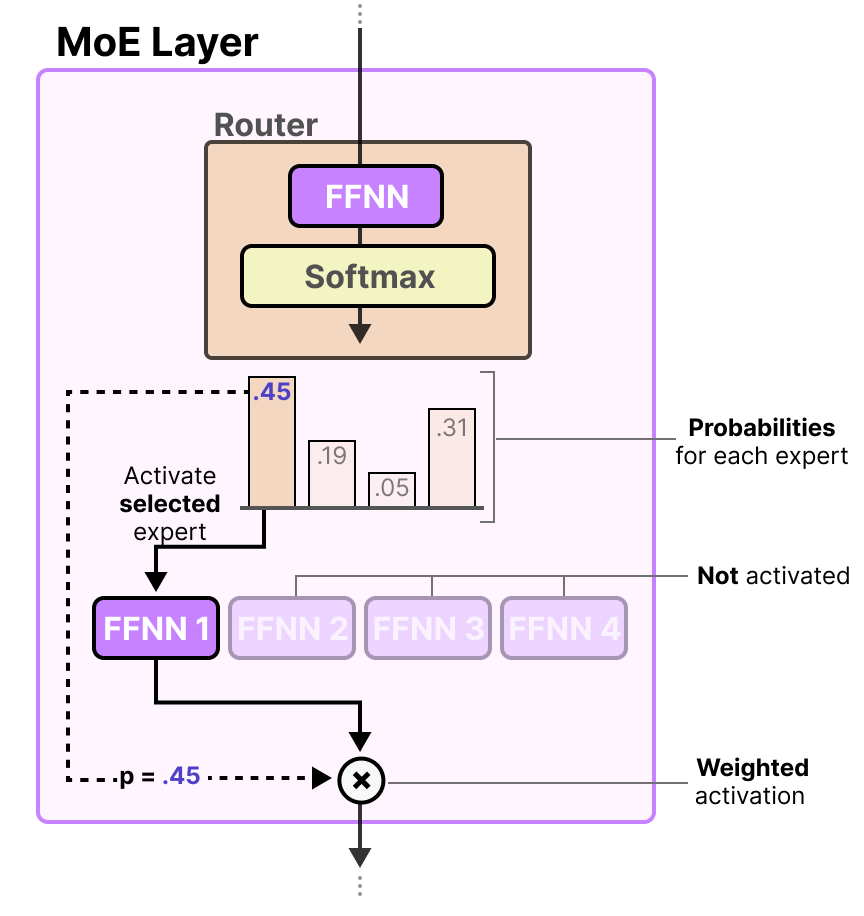
为了让专家之间产生竞争,在 Loss 上做文章,让每个专家对自己的结果负责,直接用自己的结果和目标向量做比较:
表示某条样本 表示目标向量 表示第 个专家的输出 表示 Router 给出的第 个专家的权重 表示索引 的专家的加权期望
这样的损失函数,其求导的梯度是:
这样的导数,梯度有这样的规律:
- 权重更大的专家,其更新越快
- 拟合越好的专家,其更新越慢,容易被其他专家追赶上
然而,我们希望的是,拟合越好的专家,其更新应该相对其他专家越快,这样他可以迅速超越其他专家成为这类样本的专家,所以我们对梯度的系数从
也就是说,如果某个专家做的很差,那即便 Router 分配给它的概率很高,它被选择的概率也会自然地下降。
对其做积分反推损失函数,可以得到:
将责任度的分母记作
如果
也就是说,gate 在被显式地训练去拟合责任度。
Experts 在学什么?
在 encoder / encoder–decoder MoE 中,不同的 Experts 常常学习的是特定领域中的语义,比如:某些 expert 专门处理数学、某些 expert 专门处理代码等,但是在 decoder-only LLM(GPT / Mixtral 这类)里:很少看到一个 expert 长期、稳定地绑定到某个“语义领域"。
然而,虽然没有“领域型”专精,但 experts 仍然是功能上不对称的。下面图中的 token,按 first expert choice 上色,某些颜色集中在:标点符号、function words(the, of, to, , .)、语法边界(括号、缩进、换行)等。而不是:整段“医学文本”或代码块。可以看到在 Decoder-only 架构中,专家貌似更多地是在负责语法的不同部分。

原因:自回归约束,每个 token 的 hidden state 强烈依赖当前位置、上文 token 类型。比起语义上的主题,token-level 结构信号更强。
Dense MoE & Sparse MoE
Dense MoE 的计算形式是:
也就是说:gate 给每个专家一个权重
Sparse MoE / KeepTopK :每个样本只激活 Top-K 个专家,形式上是:
gate 先算一遍选出权重最大的 K 个专家,结果只取这 K 个专家,LLM 中基本都是 Sparse。router 只对选出的 top-k 个专家负责,剩余的专家完全没有梯度。expert 的数据分布变得稀疏和可聚类。Switch Transformer 中采用 KeepTop1,而 GShard 中采用 KeepTop2。
Load Balancing
Nosiy Gating 噪声路由
Top-K 的选择会导致赢者通吃的局面,早期选中部分专家,其他专家因为没有被选中所以一直没有梯度。gate 很容易把所有样本送给少数专家,GPU/TPU 上有的专家算爆,有的专家空转,导致负载不均。所以需要在 Gate 加上一个噪声,给其他专家一些机会:
Auxiliary Loss / Load Balancing Loss
Switch Transformers 中所使用的
在 batch-level 上,我们可以定义:
- 专家
的使用频率(fraction of tokens) 记作 个 token 中,被分配到这个专家的 token 数量占整个 token 集合的比重,也就是:
- router 对于专家
在所有 Token 上分配的平均概率
Load Balancing Loss 的计算就是:
其中
也就是说,其同时惩罚了以下两种情况:
- 把大部分 token 送到同一个专家
- 对某个专家过于关注
变异系数 CV Loss
类似的,我们可以直接使用专家之间的重要性的变异系数作为惩罚,重要性即为不同 token 输入时,某个专家在 router 中的权重总和:
变异系数 = 标准差 / 均值,定义 loss 为:
亦或者等价的:
两者的区别
CV loss 只看 gate 概率,要求不同专家在 gate 的时候重要性尽可能均匀。这可能导致尽管概率变得均匀了,但最终推断时如果 KeepTop1 还是选择的同一个专家,也就是 CV Loss 可能会被绕过。
Switch 同时看 gate 的概率以及最终 routing 的结果,要求这两者都尽可能均匀,因为只有 KeepTopK 的时候,才会出现专家有的没被选中的情况,所以 Switch 天然更适合 KeepTopK 的情况。
Expert Capacity
还有一种方法,在 Gshard 模型中使用的,可以直接限制每个专家实际负责的 token 数量,如果权重最大的专家已经被选择了足够多次,达到我们设置的阈值,称作 Expert Capacity,则将其流转给权重第二大的专家,依次类推。如果该层的所有专家都已经达到了 Expert Capacity,则直接流转到下一层,称作 token overflow。
在 Switch Transformer 中,Expert Capacity 可以动态计算为:Batch中的token数量/专家数量 * 容量系数。这个系数人为设定,值越高,则更可能出现不均衡的情况,值越低,则更可能出现模型退化的情况,因为太多的 token 出现了 overflow。
视觉模型中的 MoE
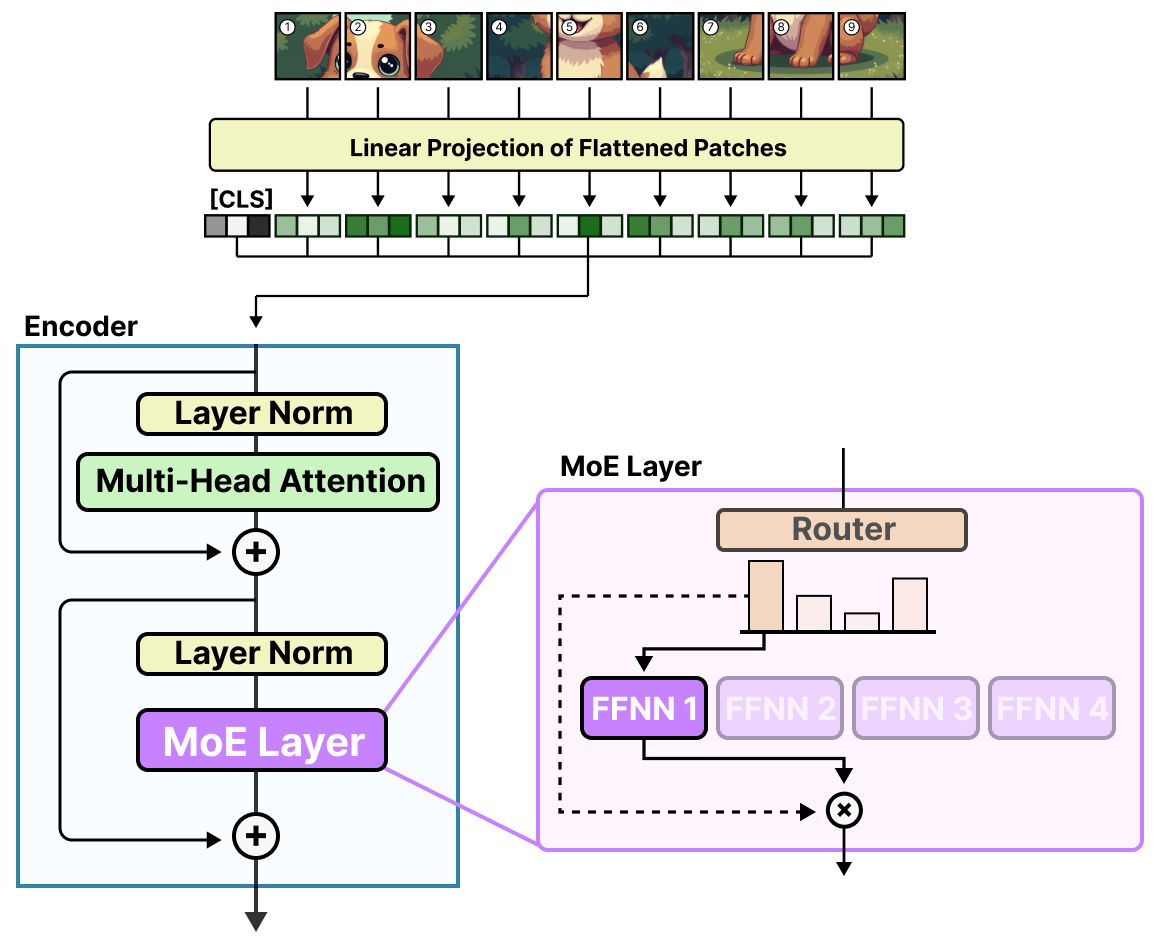
V-MoE(Vision Mixture of Experts) 是 Google 提出的 将 MoE 引入 ViT 的代表性工作。在视觉任务中,图像冗余度极高,MoE 这种条件计算带来的收益巨大。V-MoE 的核心目标是:让不同 patch 只激活一小部分 FFN expert, 在几乎不损失精度的情况下,把 ViT 的参数规模推到百亿级。
在 V-MoE 中,可以看到和 decoder-MoE 偏句法 的同一类现象:**MoE 更倾向按 representation geometry 分工,而不是人类语义。**比如按高低频/轮廓纹理分工。
DeepSeek MoE
细化粒度专家与共享专家
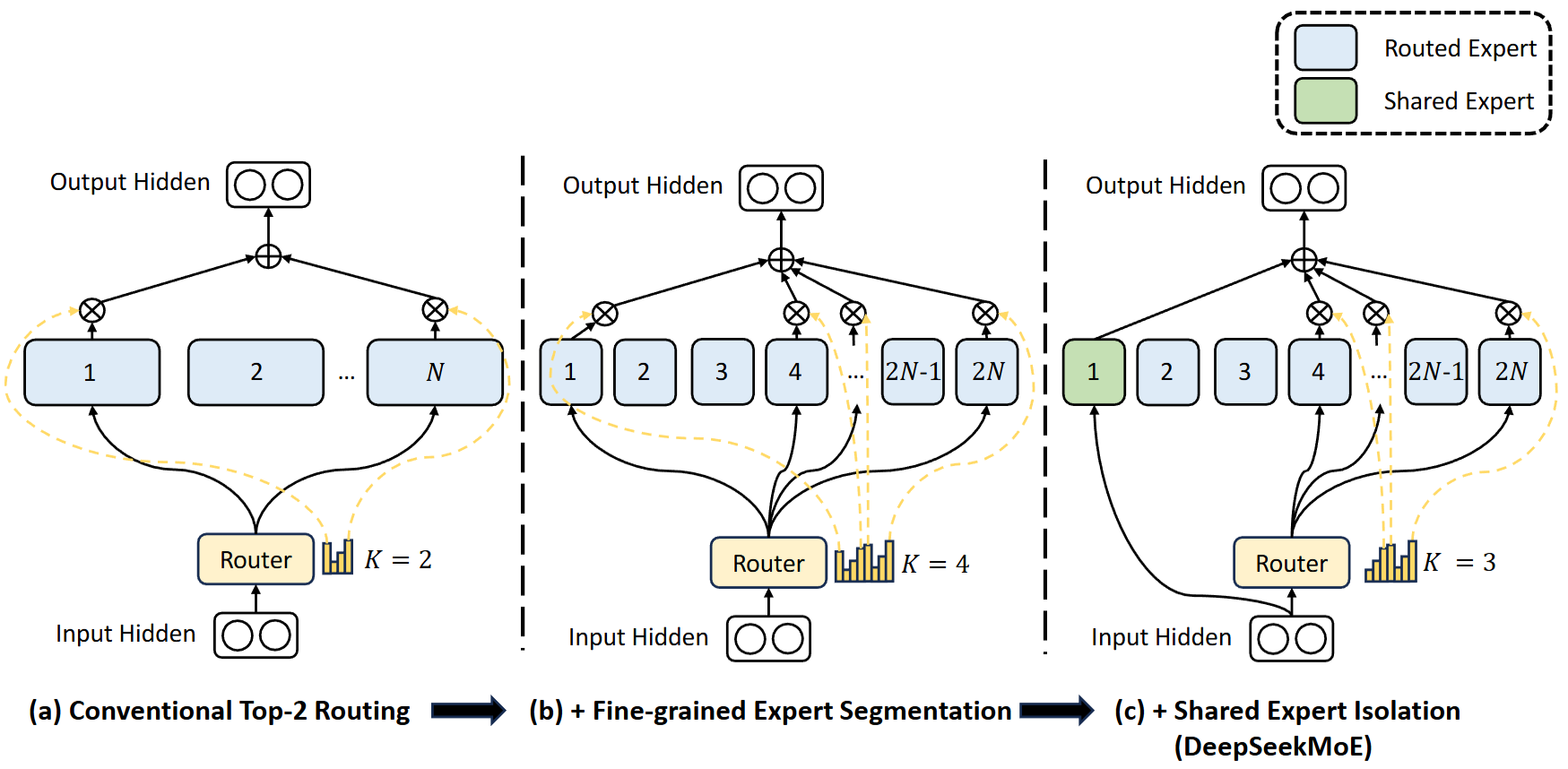
指的是在不进行 DeepSeekMoE 改造前,MoE 原始的专家数量
MoE 架构除了上面提到的负载均衡问题外,还容易出现两种问题:
- 知识混杂 knowledge hybridity:级一个专家可能同时在学习多个不同的领域知识,而这些知识又很难被同时利用,导致其参数的学习分布在不同知识上,不够专业化;
- 知识冗余 knowledge redundancy:多个专家可能在学习相同的知识,导致知识的冗余、参数的浪费;
也就是说,要提高参数利用的效率,就要做到每个专家拥有各自集中的、互不重叠的知识。DeepSeekMoE 在这方面主要做两个工作:
-
更细粒度的专家划分;将原先的每个专家的隐藏层的神经元数量划分到 1/m,同时专家变成原来的 m 倍来保持相同的参数量,KeepTopK 也变成 KeepTop mK。这样可以更灵活地对专家之间进行组合,同时每个专家学习得更加精确,维持较高得专业性。
从组合的角度上讲,这样子可以产生更多的组合数。比如
远小于 ,大大提高了专家之间组合的灵活性。 -
设立共享专家(Shared Expert Isolation):隔离出一部分专家作为共享专家,用来学习巩固跨越上下文的共同的知识。这不仅可以减少知识冗余,也可以允许不同的专家的知识集中在各自的专业领域。在固定地激活
个专家的时候,要同样减少激活其他专家的数量,变成 : 就是 MoE 的输入, 表示第 个专家在 token 上 gate 的权重,这个权重中,只有 TopK 会保留,其他的都会变成 0。
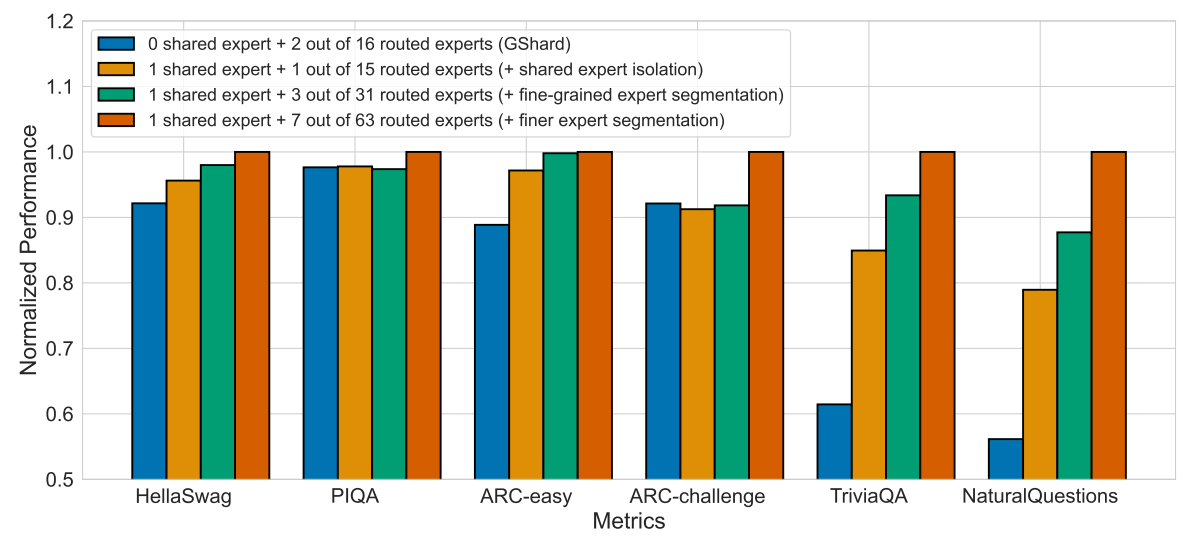
在实验上:
- DeepSeekMoE 还指出了共享专家和非共享专家的比例并不显著影响效果,但是 1:3 会有一个略微好的增益。
- 在激活的专家数和参数量更少的情况下,就可以达到和 GShard 相近 Pile Loss 水平。
Loss Balance
- 专家级别:采用Switch Transformer 的 Load Balancing Loss,但是只要求非共享的专家之间的负载均衡,同时
多乘了一个系数 。这个系数其实是在根据 K 和 N 的大小直接缩放 的大小,使其对 不那么敏感。因为一般来说, 越大,每个专家被选择的频率就越低,所以进行一个反缩放,使其保持在一个相对稳定的值域。 - 设备级别:专家级别的限制难以做到完美,因为过大的约束会降低模型的性能。所以 DeepSeekMoE 还从设备的角度上做约束,将 expert 根据其所在的设备分成 D 组,将
定义为 组内的专家的平均 ,将 定义为 组内的专家的 之和。
论文中写道,让设备级别的系数 > 专家级别的系数。
与推荐系统 MoE 的区别
和推荐系统中的 MoE/MMoE 不同,推荐系统中的 MoE 核心目标是多任务学习,解决任务之间的负迁移问题:
- 推荐系统中的 MoE 是全量激活,而LLM 中的 MoE 是稀疏激活,并不直接采用所有专家输出的加权和,而是只采用一个子集的专家的输出。
- MMoE 是在任务维度上分专家,希望是对不同的任务专家之间有差异化,减少任务的负迁移。而 MoE 是在样本维度上分专家。
参考资料
datawhalechina/so-large-lm: 大模型基础: 一文了解大模型基础知识
A Visual Guide to Mixture of Experts (MoE)
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models