GPT 技术演化历史:模型结构/数据清洗/ZeroShot/FewShot等
GPT-1(2018)
GPT 是 Decoder-Only 架构,只使用了 Transformer 的 Decoder 模块,并由于没有 Encoder 而去除了 Cross Attention 模块,保留了 Masked Attention。GPT 在 Bert 之前就提出了 Pretrain + FineTuning 的模式。
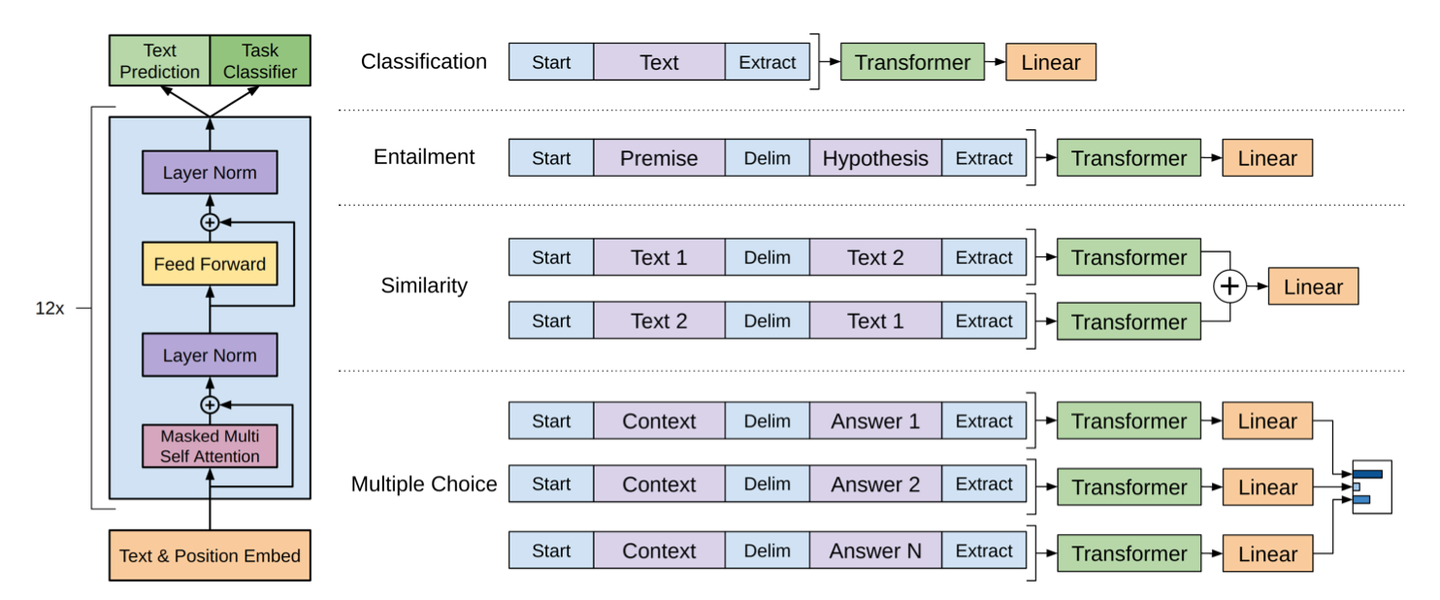
预训练
预训练阶段采用的是自监督与训练,即预测下一个词。其训练目标是最大化下一个词预测的准确性,具体而言,就是一个标准的多分类交叉熵损失:
其中
监督微调(Supervised Fine-Tuning, SFT)
GPT 将不同的 NLP 任务的输入转化为统一的序列格式,让与训练的 Transfomer 可以用统一的输入来处理他们,避免为每个任务设计特定的模型架构。主要是使用了特殊的 token 来标记句子。
对于一个有标记的输入序列
为了提高泛化能力和加速收敛,我们可以将预训练阶段的损失函数微调阶段,作为一个辅助损失,即:
Zero-shot
在 GPT-1 中虽然提到了 Zero-shot 的可能性,但是其整体效果是比较一般的。
GPT-2(2019)
GPT-2 在模型结构上,除了把模型变得更大之外(1.17 亿到 15 亿)、上下文长度从 512 扩大到 1024、以及用更大的 batch size 之外,做了两个细节优化:Pre-LN 和权重初始化缩放。
Pre-LN
Layer Normalization 从 Post-LN 变成 Pre-LN:
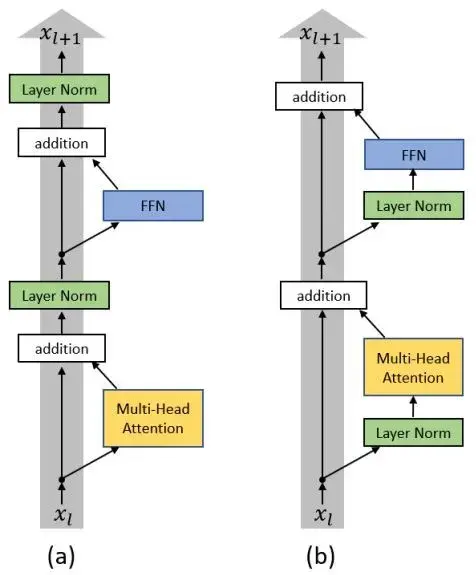
Post-LN 的结构(经典 Transformer),LN 在残差连接之后:
反向传播时:
这导致了梯度必须经过 LayerNorm 的 Jacobia,即使是 residual 分支,也必须乘以
Pre-LN 的结构
反向传播:
梯度中始终存在一条纯 identity path不经过
权重初始化
显式减小每一层残差分支在初始化时对主干信号的扰动幅度,从而保证深层网络的稳定性。GPT-2 对残差分支中线性层的权重做了如下缩放初始化:
其中
**原因:**如果每个参与残差连接的权重在初始化时的方差是 1,那输出的方差就会变成
Zero-shot 能力提升
在 GPT-2 的原始论文中,模型并未针对任何下游任务 SFT,而是直接在大规模的数据上预训练,然后直接在各种 NLP 任务上测试。也就是现在广为人知的 Prompt。
GPT-2 的核心假设是:语言建模目标本身隐含了学习多种任务的能力。具体来说:
-
任务表述为文本序列:论文中指出,许多NLP任务都可以被表述为一个文本生成问题。例如:
- 翻译任务可以表示为:
translate to French, English text, French text - 阅读理解任务可以表示为:
answer the question, document, question, answer - 摘要任务可以通过提示词如
TL;DR:来触发
- 翻译任务可以表示为:
-
条件概率建模:语言模型的目标是建模序列的条件概率:
在训练过程中,模型接触到的WebText数据集中自然包含了各种任务的自然语言表述(如翻译、问答、摘要等),这些表述以文本形式存在,模型在预测下一个词时,隐含地学习到了“任务”与“输出”之间的关系。
论文强调:模型容量是Zero-Shot泛化能力的关键。随着参数量的增加(从1.17亿到15亿),模型在几乎所有任务上的Zero-Shot性能均呈现对数线性提升。这表明:
- 更大模型能更好地捕捉任务结构:在训练中更有效地从文本中提取“任务模式”。
- 更大模型能更好地泛化到新任务:即使未见过某些任务的训练数据,也能通过类比和模式匹配进行推理。
数据清洗
只爬取Reddit上获得至少3个“karma”(点赞)的外链,从4500万个Reddit外链中提取文本,经过去重和清洗后得到约800万个文档。移除了所有 Wikipedia 数据,以避免与下游评测数据集(如SQuAD、GLUE等)重叠,影响泛化性评估。
字节级的 BPE
根据字节对来分词。步骤:
- 初始化:将词表
初始化为字节的 Unique Set - 增加词:
- 在输入语料中找到出现次数最多的字节对,比如
- 将
加入到 中 - 将语料中所有
从原先的 和 分成两个词元替换成 这个新词元
- 在输入语料中找到出现次数最多的字节对,比如
- 终止:词表达到指定大小
对于 Unicode 编码的语料,比如中文,也可以直接在字节级别进行分词。可以不同语言中的词汇同样表示为字节序列,从而更好地处理多语言数据
优点:
- 编码效率高,高频词单一token,低频词则被分解,整体上用更少的token表示更长的文本
- 无需语言学知识
- 能将未知词分解为已知子词
- 可分解词根与词缀
- 相似词源或书写系统的语言可能共享子词(如拉丁字母语言的常见前缀/后缀)帮助模型实现跨语言迁移
- 对所有语言使用同一BPE词表,避免为每种语言设计独立分词器,简化多语言模型架构
缺点:
- BPE词表可能被高资源语言主导,挤压低资源语言的子词表示 解决:过采样和欠采样
- 词表在离线训练阶段基于整个语料库的全局统计生成。但在在线推理阶段,分词是贪婪的、确定性的(例如,总是从最长匹配开始)。这可能导致分词结果不是全局最优的,且在不同上下文中分词方式固定,缺乏灵活性。
- 当需要扩展词表(如增加新领域、新语言数据)时,BPE不能简单地合并两个现有词表。必须重新在混合数据上运行整个BPE算法,这非常耗时,且会改变所有token的ID,导致与旧模型不兼容。
- 与Unigram Language Model分词不同,BPE词表本身不包含每个子词的概率。它只是一个确定的合并列表。这意味着在分词时,无法基于概率选择最优的分词路径
GPT-3 (2020)
GPT-3 继续追求更大的数据集和更大的模型,分词器则完全复用 GPT-2 的 BPE 分词器。
数据清洗(原论文的 Appendix A)
质量判定
使用了一个自动分类器来预测文档的“质量分数”。分类器使用 WebText、Wikipedia 和 Books 等高质量语料 作为正样本,使用未经过滤的 Common Crawl 作为负样本。使用逻辑回归模型,特征来自 Spark 的标准分词器和哈希词频。保留文档的条件是:
这样做的目的是大部分地保留高分文档,同时保留一些长尾的低分的样本:
- 避免所有中等质量文档被一刀切,让一些边缘案例有机会进入训练集,增加数据多样性。
- 避免完全信任分类器,分类器的任何偏见都会被放大。随机性起到了正则化的作用。
Note
Spark 的标准分词器和哈希词频:指的是 Apache Spark 这个大数据处理框架中,MLlib 机器学习库提供的两个标准文本处理工具:
Tokenizer/RegexTokenizer:用于将文本拆分成单词(Token),使用的是按照空格/标点符号规则。HashingTF:用于将单词列表(文档)转换为固定长度的数值特征向量:- 哈希:对每个单词应用一个哈希函数,将其直接映射到一个固定范围内的一个整数索引(例如,映射到 0 到 2^20 - 1 之间的某个数字)。这个过程是确定性的,同一个单词总是映射到同一个索引。
- 词频:统计整个文档中,每个哈希索引对应的单词出现了多少次。
- 输出:生成一个固定长度的稀疏向量。这个向量的长度是预设的(比如 2^20),向量中每个位置的值就是对应哈希索引的单词在该文档中出现的次数。
Note
np.random.pareto(α)
可以看到,概率随着
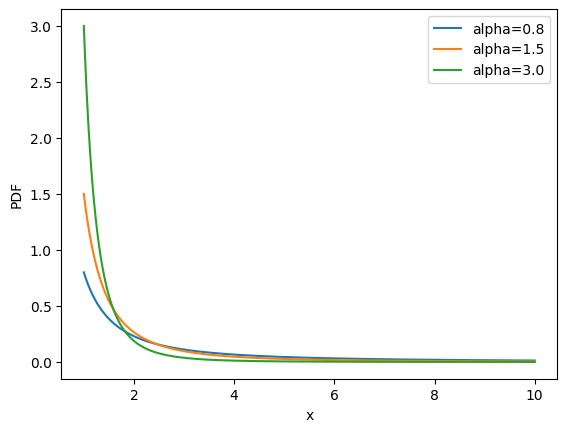
模糊去重(Fuzzy Deduplication)
去除重复或高度相似的文档,防止模型过度拟合冗余内容。使用 MinHashLSH 算法(Spark 实现)进行模糊去重,设置 10 个哈希函数。同一数据集内部以及跨数据集之间进行去重,同时,从 Common Crawl 中模糊去除了与 WebText 高度重叠的内容,去重后,数据集总体积减少了约 10%。
Note
MinHashLSH
**基本文本去重策略:**将每个文档用 3 词组(3-gram)序列的集合表示,比如 {"the cat sat", "cat sat on", "sat on the", "on the mat"},同时两个文档的相似度用 Jaccard 相似度来衡量:Jaccard(A, B) = |A ∩ B| / |A ∪ B| (交集大小/并集大小)。
MinHash 优化:对两个集合
设全集
那么有一个非常重要的性质:
右边正是 Jaccard 相似度。
工程上,并不会真的去生成所有
高质量语料及去除测试数据
在 GPT-2 被移除的 WikiPedia,在 GPT-3 重新加入,为了防止训练数据中混入测试集或基准数据集,导致评估结果被高估,使用 n-gram 重叠检测来识别并移除与基准测试集重叠的文本片段。对于检测到的重叠内容,会移除该 n-gram 及其周围 200 字符的窗口。
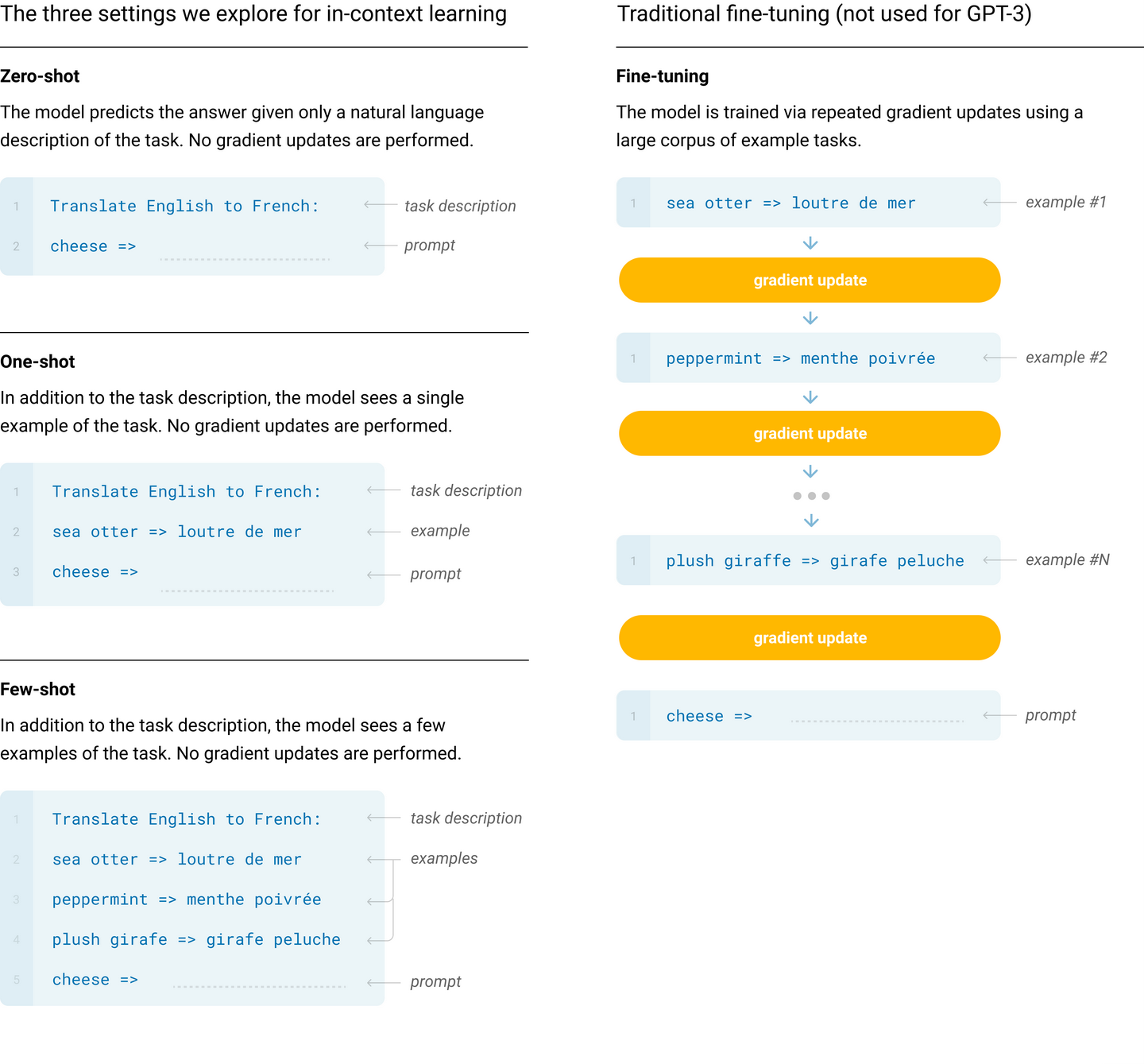
Few-shot Learning
推理时,通过在提示(Prompt)中加入少量样本来“告诉”模型要完成的具体任务,不对模型进行任何参数更新。相较于需要额外微调的做法,极大减少了特定任务的数据和计算需求。
使用 K 样本作为条件(Conditioning),在推理时,对于评估集中(test set)的每一个测试样本,模型都会:
- 从对应任务的训练集中随机选出 K 个示例样本。
- 将这 K 条示例样本(上下文 + 正确答案)与当前测试样本的上下文拼接在一起,作为模型的输入(Prompt)。
- 让模型根据提示(Prompt)来生成答案。
GPT-4
小规模模型用于损失预测
研究人员使用一系列小规模模型(计算量仅为 GPT-4 的 1/1000 到 1/10000)进行训练,为一些 idea 提前探路,可以拟合出随着参数量的变大,损失的变化规律。保持所有条件不变,只改变模型大小和训练计算量,然后观察一个固定评估指标(损失)的变化规律。在这些小模型上,他们拟合了一个幂律损失函数:
有些任务(如 Inverse Scaling Prize 中的任务)在模型规模增大时性能反而下降。但是他们发现 GPT-4 在某些此类任务(如 Hindsight Neglect)上 逆转了这种趋势,表现出更好的性能。也就是说,可能出现一个 U 型的趋势。
Note
在谷歌发布的论文 《Inverse scaling can become U-shaped》中,提出了这样的假设:
每个 Inverse Scaling 的任务可以分解为两个任务 (1)「true task」和 (2) 影响性能的「distractor task」。由于小模型不能完成这两个任务,只能达到随机准确度附近的性能。中等模型可能会执行「distractor task」,这会导致性能下降。大型模型能够忽略分「distractor task」,执行「true task」让性能的提高,并有可能解决任务。
也就是说,呈现这样的规律:
1 | 小规模 → 中等规模 → 超大规模 |
RLHF
Reinforcement Learning from Human Feedback, RLHF,人类反馈强化学习
GPT-4 的论文中并没有介绍 RLHF 的具体细节,但是提到了 RLHF 对模型的影响,会让模型过度自信:
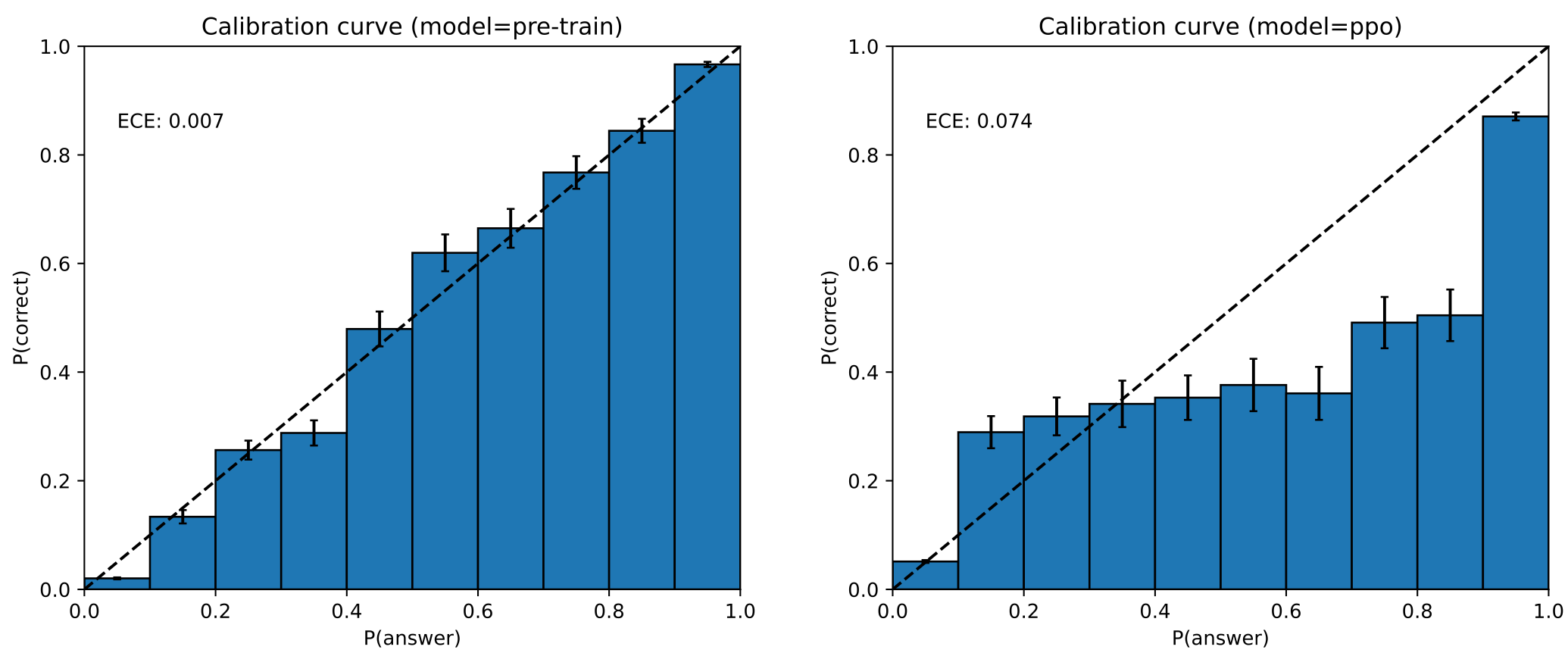
图中是校准度的图像,反映模型自信度与真实正确率之间的匹配度。可以看到,在 PPO 学习之后,其校准度明显下降偏离
参考文献
GPT 系列论文精读:从 GPT-1 到 GPT-4 - 知乎
GPT-1 Improving Language Understanding by Generative Pre-Training
GPT-2 Language Models are Unsupervised Multitask Learners
GPT-3 Language Models are Few-Shot Learners
GPT-4 GPT-4 Technical Report